Как написать свою операционную систему. Как создать свою собственную операционную систему с нуля
Данный цикл статей посвящён низкоуровневому программированию, то есть архитектуре компьютера, устройству операционных систем, программированию на языке ассемблера и смежным областям. Пока что написанием занимаются два хабраюзера - iley и pehat . Для многих старшеклассников, студентов, да и профессиональных программистов эти темы оказываются весьма сложными при обучении. Существует много литературы и курсов, посвящённых низкоуровневому программированию, но по ним сложно составить полную и всеохватывающую картину. Сложно, прочитав одну-две книги по ассемблеру и операционным системам, хотя бы в общих чертах представить, как же на самом деле работает эта сложная система из железа, кремния и множества программ - компьютер.
Каждый решает проблему обучения по-своему. Кто-то читает много литературы, кто-то старается поскорее перейти к практике и разбираться по ходу дела, кто-то пытается объяснять друзьям всё, что сам изучает. А мы решили совместить эти подходы. Итак, в этом курсе статей мы будем шаг за шагом демонстрировать, как пишется простая операционная система. Статьи будут носить обзорный характер, то есть в них не будет исчерпывающих теоретических сведений, однако мы будем всегда стараться предоставить ссылки на хорошие теоретические материалы и ответить на все возникающие вопросы. Чёткого плана у нас нет, так что многие важные решения будут приниматься по ходу дела, с учётом ваших отзывов.
Возможно, мы умышленно будем заводить процесс разработки в тупик, чтобы позволить вам и себе полностью осознать все последствия неверно принятого решения, а также отточить на нем некоторые технические навыки. Так что не стоит воспринимать наши решения как единственно верные и слепо нам верить. Еще раз подчеркнём, что мы ожидаем от читателей активности в обсуждении статей, которая должна сильно влиять на общий процесс разработки и написания последующих статей. В идеале хотелось бы, чтобы со временем некоторые из читателей присоединились к разработке системы.
Мы будем предполагать, что читатель уже знаком с основами языков ассемблер и Си, а также элементарными понятиями архитектуры ЭВМ. То есть, мы не будем объяснять, что такое регистр или, скажем, оперативная память. Если вам не будет хватать знаний, вы всегда можете обратиться к дополнительной литературе. Краткий список литературы и ссылки на сайты с хорошими статьями есть в конце статьи. Также желательно уметь пользоваться Linux, так как все инструкции по компиляции будут приводиться именно для этой системы.
А теперь - ближе к делу. В оставшейся части статьи мы с вами напишем классическую программу «Hello World». Наш хеллоуворлд получится немного специфическим. Он будет запускаться не из какой-либо операционной системы, а напрямую, так сказать «на голом железе». Перед тем, как приступить непосредственно к написанию кода, давайте разберёмся, как же конкретно мы пытаемся это сделать. А для этого надо рассмотреть процесс загрузки компьютера.
Итак, берем свой любимый компьютер и нажимаем самую большую кнопочку на системном блоке. Видим веселую заставку, системный блок радостно пищит спикером и через какое-то время загружается операционная система. Как вы понимаете, операционная система хранится на жёстком диске, и вот тут возникает вопрос: а каким же волшебным образом операционная система загрузилась в ОЗУ и начала выполняться?
Знайте же: за это отвечает система, которая есть на любом компьютере, и имя ей - нет, не Windows, типун вам на язык - называется она BIOS. Расшифровывается ее название как Basic Input-Output System, то есть базовая система ввода-вывода. Находится BIOS на маленькой микросхемке на материнской плате и запускается сразу после нажатия большой кнопки ВКЛ. У BIOS три главных задачи:
- Обнаружить все подключенные устройства (процессор, клавиатуру, монитор, оперативную память, видеокарту, голову, руки, крылья, ноги и хвосты…) и проверить их на работоспособность. Отвечает за это программа POST (Power On Self Test – самотестирование при нажатии ВКЛ). Если жизненно важное железо не обнаружено, то никакой софт помочь не сможет, и на этом месте системный динамик пропищит что-нибудь зловещее и до ОС дело вообще не дойдет. Не будем о печальном, предположим, что у нас есть полностью рабочий компьютер, возрадуемся и перейдем к рассмотрению второй функции BIOS:
- Предоставление операционной системе базового набора функций для работы с железом. Например, через функции BIOS можно вывести текст на экране или считать данные с клавиатуры. Потому она и называется базовой системой ввода-вывода. Обычно операционная система получает доступ к этим функциям посредством прерываний.
- Запуск загрузчика операционной системы. При этом, как правило, считывается загрузочный сектор - первый сектор носителя информации (дискета, жесткий диск, компакт-диск, флэшка). Порядок опроса носителей можно задать в BIOS SETUP. В загрузочном секторе содержится программа, иногда называемая первичным загрузчиком. Грубо говоря, задача загрузчика - начать запуск операционной системы. Процесс загрузки операционной системы может быть весьма специфичен и сильно зависит от её особенностей. Поэтому первичный загрузчик пишется непосредственно разработчиками ОС и при установке записывается в загрузочный сектор. В момент запуска загрузчика процессор находится в реальном режиме.
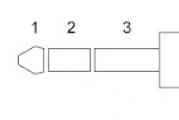
На картинке изображена поверхность дискового накопителя. У дискеты 2 поверхности. На каждой поверхности есть кольцеобразные дорожки (треки). Каждый трек делится на маленькие дугообразные кусочки, называемые секторами. Так вот, исторически сложилось, что сектор дискеты имеет размер 512 байт. Самый первый сектор на диске, загрузочный сектор, читается BIOS"ом в нулевой сегмент памяти по смещению 0x7С00, и дальше по этому адресу передается управление. Начальный загрузчик обычно загружает в память не саму ОС, а другую программу-загрузчик, хранящуюся на диске, но по каким-то причинам (скорее всего, эта причина - размер) не влезающую в один сектор. А поскольку пока что роль нашей ОС выполняет банальный хеллоуворлд, наша главная цель - заставить компьютер поверить в существование нашей ОС, пусть даже и на одном секторе, и запустить её.
Как устроен загрузочный сектор? На PC единственное требование к загрузочному сектору - это содержание в двух его последних байтах значений 0x55 и 0xAA - сигнатуры загрузочного сектора. Итак, уже более-менее понятно, что нам нужно делать. Давайте же писать код! Приведённый код написан для ассемблера yasm .
Section .text use16 org 0x7C00 ; наша программа загружается по адресу 0x7C00 start: mov ax, cs mov ds, ax ; выбираем сегмент данных mov si, message cld ; направление для строковых команд mov ah, 0x0E ; номер функции BIOS mov bh, 0x00 ; страница видеопамяти puts_loop: lodsb ; загружаем очередной символ в al test al, al ; нулевой символ означает конец строки jz puts_loop_exit int 0x10 ; вызываем функцию BIOS jmp puts_loop puts_loop_exit: jmp $ ; вечный цикл message: db "Hello World!", 0 finish: times 0x1FE-finish+start db 0 db 0x55, 0xAA ; сигнатура загрузочного сектора
Эта короткая программа требует ряда важных пояснений. Строка org 0x7C00 нужна для того, чтобы ассемблер (имеется в виду программа, а не язык) правильно рассчитал адреса для меток и переменных (puts_loop, puts_loop_exit, message). Вот мы ему и сообщаем, что программа будет загружена в память по адресу 0x7C00.
В строках
mov ax, cs
mov ds, ax
происходит установка сегмента данных (ds) равным сегменту кода (cs), поскольку в нашей программе и данные, и код хранятся в одном сегменте.
Далее в цикле посимвольно выводится сообщение «Hello World!». Для этого используется функция 0x0E прерывания 0x10 . Она имеет следующие параметры:
AH = 0x0E (номер функции)
BH = номер видеостраницы (пока не заморачиваемся, указываем 0)
AL = ASCII-код символа
В строке « jmp $ » программа зависает. И правильно, незачем ей выполнять лишний код. Однако чтобы компьютер опять заработал, придется перезагрузиться.
В строке « times 0x1FE-finish+start db 0 » производится заполнение остатка кода программы (за исключением последних двух байт) нулями. Делается это для того, чтобы после компиляции в последних двух байтах программы оказалась сигнатура загрузочного сектора.
С кодом программы вроде разобрались, давайте теперь попробуем скомпилировать это счастье. Для компиляции нам понадобится, собственно говоря, ассемблер - выше упомянутый yasm . Он есть в большинстве репозиториев Linux. Программу можно откомпилировать следующим образом:
$ yasm -f bin -o hello.bin hello.asm
Полученный файл hello.bin нужно записать в зарузочный сектор дискеты. Делается это примерно так (разумеется, вместо fd нужно подставить имя своего дисковода).
$ dd if=hello.bin of=/dev/fd
Поскольку далеко не у всех остались дисководы и дискеты, можно воспользоваться виртуальной машиной, например, qemu или VirtualBox . Для этого придётся сделать образ дискеты с нашим загрузчиком и вставить его в «виртуальный дисковод».
Создаём образ диска и заполняем его нулями:
$ dd if=/dev/zero of=disk.img bs=1024 count=1440
Записываем в самое начало образа нашу программу:
$ dd if=hello.bin of=disk.img conv=notrunc
Запускаем полученный образ в qemu:
$ qemu -fda disk.img -boot a
После запуска вы должны увидеть окошко qemu с радостной строчкой «Hello World!». На этом первая статья заканчивается. Будем рады увидеть ваши отзывы и пожелания.
Что нужно знать, чтобы написать операционную систему
Создание операционной системы - одна из сложнейших задач в программировании, поскольку требует обширных и комплексных знаний о работе компьютера. Каких именно? Разбираемся ниже.
Что такое ОС
Операционная система (ОС) - это программное обеспечение, которое работает с компьютерным железом и его ресурсами и является мостом между аппаратной и программной частью компьютера.
Компьютеры первого поколения не имели операционных систем. Программы на первых ЭВМ включали в себя код для непосредственной работы системы, связи с периферийными устройствами и вычислений, для выполнения которых эта программа и писалась. Из-за такого расклада даже простые по логике работы программы были сложны в программной реализации.
По мере того как компьютеры становились более разнообразными и сложными, писать программы, которые работали и как ОС, и как приложение, стало попросту неудобно. Поэтому, чтобы программы было легче писать, владельцы компьютеров начали разрабатывать программное обеспечение. Так и появились операционные системы.
ОС предоставляет всё необходимое для работы пользовательских программ. Их появление означало, что теперь программам не нужно контролировать весь объём работ компьютера (это отличный пример инкапсуляции). Теперь программам нужно было работать именно с операционной системой, а система уже сама заботилась о ресурсах и работе с периферией (клавиатура, принтер).
Кратко об истории операционных систем
Язык Cи
Как уже упоминалось выше, для написания ОС есть несколько высокоуровневых языков программирования. Однако самый популярный из них - Си.
Начать изучать этот язык можно отсюда . Этот ресурс ознакомит вас с базовыми понятиями и подготовит к более сложным задачам.
«Learn C the Hard Way » - название ещё одной книги. Кроме привычной теории в ней собрано много практических решений. Этот учебник расскажет обо всех аспектах языка.
Либо же можете выбрать одну из этих книг:
- «The C Programming Language » Кернигхана и Ритчи;
- «C Programming Absolute Beginner’s Guide » Пэрри и Миллера.
Разработка ОС
После освоения всего необходимого, что касается информатики, языка ассемблера и Cи, вам стоит прочесть хотя бы одну или две книги про непосредственную разработку ОС. Вот несколько ресурсов для этого:
«Linux From Scratch ». Здесь рассматривается процесс сборки операционной системы Linux (учебник переведён на много языков, в том числе и на русский). Тут, как и в остальных учебниках, вам предоставят все необходимые базовые знания. Полагаясь на них можно попробовать себя в создании ОС. Чтобы сделать программную часть ОС более профессиональной, присутствуют дополнения к учебнику: «
Автор Vulf gamer задал вопрос в разделе Другие языки и технологии
Как создать свою ОС? и получил лучший ответ
Ответ от Александр Багров[гуру]
Идея похвальная.
Прежде всего нужно знать систему команд машины, для которой намереваешься писать ОС.
Система команд находит свое прямое отражение в языке ассемблера.
Поэтому в первую очередь нужно придумать свой язык ассемблера и написать для него программу (ассемблер) , транслирующий буквенно-цифровую символику в машинный
код.
Если интересно, то можно посмотреть, какими бы требования должна обладать новая (идеальная) ОС.
Некоторые такие черты перечислены тут:
.ru/D_OS/OS-PolyM.html#IdealOS
Необходимо изучать материалы сайтов-разработчиков микропроцессоров. Например, Intel и AMD.
Возможно, тебе будет полезен видео-курс лекций по ОС, который представлен здесь:
.ru/D_OS/OS_General.html
PS: Не слушай пессимистов. Исходи из идеологии петуха, гонящегося за курицей:
"Не догоню, хоть разогреюсь. "
Источник: Сайт "Используй ПК правильно! "
Ответ от 2 ответа
[гуру]
Привет! Вот подборка тем с ответами на Ваш вопрос: Как создать свою ОС?
Ответ от Вадим Хпрламов
[новичек]
Конечно) Тут-же одни гейтсы сидят) На майкрософте спроси)
Ответ от Ирина стародубцева
[новичек]
возьми все ОС и в одну запихай
Ответ от Александр Тунцов
[гуру]
Ознакомься с ОС Linux, обучись программированию и в путь
Ответ от ~In Flames~
[гуру]
Программирование учить на высшем уровне, собрать целую толпу таких же компьютерных гениев и тогда уже можно делать.
Ответ от Rasul Magomedov
[гуру]
Начни с создания нескучных обоев
Ответ от Капитан Гугл
[гуру]
Про "10 лет на изучение основ" - не слушай, Торвальдс первую версию Линукса написал в 22 года, а компьютер у него в 12 появился. Как ты понимаешь, он не только основы изучал.
Начни с изучения уже существующего - с одной стороны, "Современные операционные системы" Танненбаума, с другой стороны - собери Linux From Scratch, с третьей - учи Ассемблер, C, C++. За все про все - можно в 3-4 года уложиться. После этого можешь приступать к разработке своей системы... если еще захочешь.
Ответ от Ёаня Семенов
[гуру]
знаешь как делал Гейтс? попробуй так же, говорят прибыльно получается..
когда его наказали родители, он от нечего делать стал прыгать попой на клаве, потом продал назвав то что получилось " windows "
п с а если реально то напиши сначала "Hello World" в С++ и сразу поймешь что идея параноидальная
Ответ от Kostafey
[гуру]
А зачем? Чем принципиально не устраивают существующие? Неужели нет ни одной, хоть частично удовлетворяющей вашим требованиям к ОС? Может стоит лучше присоединиться к команде разработчиков? Толку в 100500 раз больше будет.
И потом, вы забросите эту идею еще на 0,(0)1% ее реализации.
Ответ от Евгений Ломега
[гуру]
Э. Таненбаум "Операционные системы: разработка и реализация "
удачи
PS К сожалению как это делал Бил Гейтс у тебя вряд ли получится. У него мама крутая банкирша, у тебя?
Ответ от Krab Bark
[гуру]
Написать простейшую ОС самому можно, но она никак не сможет конкурировать с ОС вроде Windows, MAC OS или Linux, над которыми минимум десяток лет трудились сотни или тысячи программистов. Кроме того, ОС - только фундамент. Нужно, чтобы разработчики оборудования писали для этой ОС свои драйверы, разработчики прикладных программ писали для нее редакторы, плееры, браузеры, игры, черта в ступе... А без этого ОС останется никому не нужным фундаментом для дома, который никто строить не будет.
Ответ от Вадим Стаханов
[активный]
Лучше бы на филолога пошел бы учится. А потом бы кричал "Свободная касса! "
Ответ от =Serge=
[гуру]
Ура! Наконец то 58 вопрос на сайте про создание "своей" ОС))
Вот вопросы про "написать свою ОС" - их только 34))
Читай....92 вопроса*10 ответов = приблизительно 920 ответов))
Заодно возможно поймешь что значат "нескучные обои")).
Ответ от Irreproducible
[гуру]
еще один Денис Попов с очередным BolgenOS"ом?
Ответ от Иван татарчук
[новичек]
запусти блокнот скачай компилятор жабаскрипт и начни прыгать попой по клавиатуре
через 60мин компилируй и все
твоя оска готова
Ответ от Овечка Мила
[новичек]
ОС? Какая именно? ОС-орижинал честер (оригинальный персонаж (в переводе))
Она нужна доя изображения себя мультиках или фильмах.
1. Придумай какого именно мультика/фильма ты хочешь ОС
2. Рассмотрим стиль мультика/фильма
3. Кем будет твой персонаж (фея, пони, маг, робот и т. п.)
4. Опиши мысленно его, потом на бумаге
5. Придумай дизайн
6. Придумай имя и био
7. Нарисуй персонажа!
8. Теперь за дело с Пэинт Туд Саи
Оригинал: "Roll your own toy UNIX-clone OS"
Автор: James Molloy
Дата публикации: 2008
Перевод: Н.Ромоданов
Дата перевода: январь 2012 г.
Этот набор руководств предназначен для того, чтобы подробно показать вам, как запрограммировать простую UNIX-подобную операционную систему для архитектуры x86. В этих руководствах в качестве языка программирования выбран язык C, который дополняется языком ассемблера там, где это требуется. Цель руководств - рассказать вам о разработке и реализации решений, используемых при создании операционной системы ОС, которую мы создаем, монолитную по своей структуре (драйверы загружаются в режиме модулей ядра, а не в пользовательском режиме так, как происходит с программами), поскольку такое решение более простое.
Этот набор руководств очень практический по своей природе. В каждом разделе приводятся теоретические сведения, но большая часть руководства касается вопросов реализации на практике рассмотренных абстрактных идей и механизмов. Важно отметить, что ядро реализовано как учебное. Я знаю, что используемые алгоритмы не являются ни самыми эффективными по использованию пространства, ни оптимальными. Они, как правило, выбирались благодаря своей простоте и легкости понимания. Целью этого является дать вам правильный настрой и предоставить базис, на котором можно работать. Данное ядро является расширяемым и можно легко подключить лучшие алгоритмы. Если у вас возникнут проблемы, касающиеся теории, то есть много сайтов, на которых вам помогут с ней разобраться. Большинство вопросов, обсуждаемых на форуме OSDev, касаются реализации ("My gets function doesn"t work! help!" / "Моя функция не работает! Помогите!") и для многих вопрос по теории похож на глоток свежего воздуха. Ссылки можно найти в конце настоящего введения.
Предварительная подготовка
Чтобы скомпилировать и запустить код с примерами, как я предполагаю, потребуется только GCC, ld, NASM и GNU Make. NASM является ассемблером для x86 с открытым исходным кодом и многие разработчики ОС для платформы x86 выбирают именно его.
Однако нет никакого смысла просто выполнять компиляцию и запускать примеры, если нет их понимания. Вы должны понять, что кодируется, и для этого вы должны очень хорошо знать язык C, особенно то, что касается указателей. Вы также должны немного понимать ассемблер (в этих руководствах используется синтаксис Intel), в том числе то, для чего используется регистр EBP.
Ресурсы
Есть много ресурсов, если вы знаете, как их искать . В частности, вам будут полезны следующие ссылки:
- RTFM! Руководства от intel - это находка.
- Wiki страницы и форум сайта osdev.org.
- На сайте Osdever.net есть много хороших руководств и статей и, в частности, Bran"s kernel development tutorials (Руководство по разработке ядра), на более раннем коде которого основывается настоящее руководство. Я сам использовал эти руководства для того, чтобы начать работу, и код в них был настолько хорош, что я не менял его в течение ряда лет.
- Если вы не новичок, то ответы на многие вопросы вы можете получить в группе
Разработка ядра по праву считается задачей не из легких, но написать простейшее ядро может каждый. Чтобы прикоснуться к магии кернел-хакинга, нужно лишь соблюсти некоторые условности и совладать с ассемблером. В этой статье мы на пальцах разберем, как это сделать.
Привет, мир!
Давай напишем ядро, которое будет загружаться через GRUB на системах, совместимых с x86. Наше первое ядро будет показывать сообщение на экране и на этом останавливаться.
Как загружаются x86-машины
Прежде чем думать о том, как писать ядро, давай посмотрим, как компьютер загружается и передает управление ядру. Большинство регистров процессора x86 имеют определенные значения после загрузки. Регистр - указатель на инструкцию (EIP) содержит адрес инструкции, которая будет исполнена процессором. Его захардкоженное значение - это 0xFFFFFFF0. То есть x86-й процессор всегда будет начинать исполнение с физического адреса 0xFFFFFFF0. Это последние 16 байт 32-разрядного адресного пространства. Этот адрес называется «вектор сброса» (reset vector).
В карте памяти, которая содержится в чипсете, прописано, что адрес 0xFFFFFFF0 ссылается на определенную часть BIOS, а не на оперативную память. Однако BIOS копирует себя в оперативку для более быстрого доступа - этот процесс называется «шедоуинг» (shadowing), создание теневой копии. Так что адрес 0xFFFFFFF0 будет содержать только инструкцию перехода к тому месту в памяти, куда BIOS скопировала себя.
Итак, BIOS начинает исполняться. Сначала она ищет устройства, с которых можно загружаться в том порядке, который задан в настройках. Она проверяет носители на наличие «волшебного числа», которое отличает загрузочные диски от обычных: если байты 511 и 512 в первом секторе равны 0xAA55, значит, диск загрузочный.
Как только BIOS найдет загрузочное устройство, она скопирует содержимое первого сектора в оперативную память, начиная с адреса 0x7C00, а затем переведет исполнение на этот адрес и начнет исполнение того кода, который только что загрузила. Вот этот код и называется загрузчиком (bootloader).
Загрузчик загружает ядро по физическому адресу 0x100000. Именно он и используется большинством популярных ядер для x86.
Все процессоры, совместимые с x86, начинают свою работу в примитивном 16-разрядном режиме, которые называют «реальным режимом» (real mode). Загрузчик GRUB переключает процессор в 32-разрядный защищенный режим (protected mode), переводя нижний бит регистра CR0 в единицу. Поэтому ядро начинает загружаться уже в 32-битном защищенном режиме.
Заметь, что GRUB в случае с ядрами Linux выбирает соответствующий протокол загрузки и загружает ядро в реальном режиме. Ядра Linux сами переключаются в защищенный режим.
Что нам понадобится
- Компьютер, совместимый с x86 (очевидно),
- Linux,
- ассемблер NASM,
- ld (GNU Linker),
- GRUB.
Входная точка на ассемблере
Нам бы, конечно, хотелось написать все на C, но совсем избежать использования ассемблера не получится. Мы напишем на ассемблере x86 небольшой файл, который станет стартовой точкой для нашего ядра. Все, что будет делать ассемблерный код, - это вызывать внешнюю функцию, которую мы напишем на C, а потом останавливать выполнение программы.
Как сделать так, чтобы ассемблерный код стал стартовой точкой для нашего ядра? Мы используем скрипт для компоновщика (linker), который линкует объектные файлы и создает финальный исполняемый файл ядра (подробнее объясню чуть ниже). В этом скрипте мы напрямую укажем, что хотим, чтобы наш бинарный файл загружался по адресу 0x100000. Это адрес, как я уже писал, по которому загрузчик ожидает увидеть входную точку в ядро.
Вот код на ассемблере.
kernel.asm
bits 32 section .text global start extern kmain start: cli mov esp, stack_space call kmain hlt section .bss resb 8192 stack_space:Первая инструкция bits 32 - это не ассемблер x86, а директива NASM, сообщающая, что нужно генерировать код для процессора, который будет работать в 32-разрядном режиме. Для нашего примера это не обязательно, но указывать это явно - хорошая практика.
Вторая строка начинает текстовую секцию, также известную как секция кода. Сюда пойдет весь наш код.
global - это еще одна директива NASM, она объявляет символы из нашего кода глобальными. Это позволит компоновщику найти символ start , который и служит нашей точкой входа.
kmain - это функция, которая будет определена в нашем файле kernel.c . extern объявляет, что функция декларирована где-то еще.
Далее идет функция start , которая вызывает kmain и останавливает процессор инструкцией hlt . Прерывания могут будить процессор после hlt , так что сначала мы отключаем прерывания инструкцией cli (clear interrupts).
В идеале мы должны выделить какое-то количество памяти под стек и направить на нее указатель стека (esp). GRUB, кажется, это и так делает за нас, и на этот момент указатель стека уже задан. Однако на всякий случай выделим немного памяти в секции BSS и направим указатель стека на ее начало. Мы используем инструкцию resb - она резервирует память, заданную в байтах. Затем оставляется метка, указывающая на край зарезервированного куска памяти. Прямо перед вызовом kmain указатель стека (esp) направляется на эту область инструкцией mov .
Ядро на C
В файле kernel.asm мы вызвали функцию kmain() . Так что в коде на C исполнение начнется с нее.
kernel.c
void kmain(void) { const char *str = "my first kernel"; char *vidptr = (char*)0xb8000; unsigned int i = 0; unsigned int j = 0; while(j < 80 * 25 * 2) { vidptr[j] = " "; vidptr = 0x07; j = j + 2; } j = 0; while(str[j] != "\0") { vidptr[i] = str[j]; vidptr = 0x07; ++j; i = i + 2; } return; }Все, что будет делать наше ядро, - очищать экран и выводить строку my first kernel.
Первым делом мы создаем указатель vidptr, который указывает на адрес 0xb8000. В защищенном режиме это начало видеопамяти. Текстовая экранная память - это просто часть адресного пространства. Под экранный ввод-вывод выделен участок памяти, который начинается с адреса 0xb8000, - в него помещается 25 строк по 80 символов ASCII.
Каждый символ в текстовой памяти представлен 16 битами (2 байта), а не 8 битами (1 байтом), к которым мы привыкли. Первый байт - это код символа в ASCII, а второй байт - это attribute-byte . Это определение формата символа, в том числе - его цвет.
Чтобы вывести символ s зеленым по черному, нам нужно поместить s в первый байт видеопамяти, а значение 0x02 - во второй байт. 0 здесь означает черный фон, а 2 - зеленый цвет. Мы будем использовать светло-серый цвет, его код - 0x07.
В первом цикле while программа заполняет пустыми символами с атрибутом 0x07 все 25 строк по 80 символов. Это очистит экран.
Во втором цикле while символы строки my first kernel, оканчивающейся нулевым символом, записываются в видеопамять и каждый символ получает attribute-byte, равный 0x07. Это должно привести к выводу строки.
Компоновка
Теперь мы должны собрать kernel.asm в объектный файл с помощью NASM, а затем при помощи GCC скомпилировать kernel.c в другой объектный файл. Наша задача - слинковать эти объекты в исполняемое ядро, пригодное к загрузке. Для этого потребуется написать для компоновщика (ld) скрипт, который мы будем передавать в качестве аргумента.
link.ld
OUTPUT_FORMAT(elf32-i386) ENTRY(start) SECTIONS { . = 0x100000; .text: { *(.text) } .data: { *(.data) } .bss: { *(.bss) } }Здесь мы сначала задаем формат (OUTPUT_FORMAT) нашего исполняемого файла как 32-битный ELF (Executable and Linkable Format), стандартный бинарный формат для Unix-образных систем для архитектуры x86.
ENTRY принимает один аргумент. Он задает название символа, который будет служить входной точкой исполняемого файла.
SECTIONS - это самая важная для нас часть. Здесь мы определяем раскладку нашего исполняемого файла. Мы можем определить, как разные секции будут объединены и куда каждая из них будет помещена.
В фигурных скобках, которые идут за выражением SECTIONS , точка означает счетчик позиции (location counter). Он автоматически инициализируется значением 0x0 в начале блока SECTIONS , но его можно менять, назначая новое значение.
Ранее я уже писал, что код ядра должен начинаться по адресу 0x100000. Именно поэтому мы и присваиваем счетчику позиции значение 0x100000.
Взгляни на строку.text: { *(.text) } . Звездочкой здесь задается маска, под которую подходит любое название файла. Соответственно, выражение *(.text) означает все входные секции.text во всех входных файлах.
В результате компоновщик сольет все текстовые секции всех объектных файлов в текстовую секцию исполняемого файла и разместит по адресу, указанному в счетчике позиции. Секция кода нашего исполняемого файла будет начинаться по адресу 0x100000.
После того как компоновщик выдаст текстовую секцию, значение счетчика позиции будет 0x100000 плюс размер текстовой секции. Точно так же секции data и bss будут слиты и помещены по адресу, который задан счетчиком позиции.
GRUB и мультизагрузка
Теперь все наши файлы готовы к сборке ядра. Но поскольку мы будем загружать ядро при помощи GRUB , остается еще один шаг.
Существует стандарт для загрузки разных ядер x86 с помощью бутлоадера. Это называется «спецификация мультибута ». GRUB будет загружать только те ядра, которые ей соответствуют.
В соответствии с этой спецификацией ядро может содержать заголовок (Multiboot header) в первых 8 килобайтах. В этом заголовке должно быть прописано три поля:
- magic - содержит «волшебное» число 0x1BADB002, по которому идентифицируется заголовок;
- flags - это поле для нас не важно, можно оставить ноль;
- checksum - контрольная сумма, должна дать ноль, если прибавить ее к полям magic и flags .
Наш файл kernel.asm теперь будет выглядеть следующим образом.
kernel.asm
bits 32 section .text ;multiboot spec align 4 dd 0x1BADB002 ;magic dd 0x00 ;flags dd - (0x1BADB002 + 0x00) ;checksum global start extern kmain start: cli mov esp, stack_space call kmain hlt section .bss resb 8192 stack_space:Инструкция dd задает двойное слово размером 4 байта.
Собираем ядро
Итак, все готово для того, чтобы создать объектный файл из kernel.asm и kernel.c и слинковать их с применением нашего скрипта. Пишем в консоли:
$ nasm -f elf32 kernel.asm -o kasm.o
По этой команде ассемблер создаст файл kasm.o в формате ELF-32 bit. Теперь настал черед GCC:
$ gcc -m32 -c kernel.c -o kc.o
Параметр -c указывает на то, что файл после компиляции не нужно линковать. Мы это сделаем сами:
$ ld -m elf_i386 -T link.ld -o kernel kasm.o kc.o
Эта команда запустит компоновщик с нашим скриптом и сгенерирует исполняемый файл под названием kernel .
WARNING
Хакингом ядра лучше всего заниматься в виртуалке. Чтобы запустить ядро в QEMU вместо GRUB, используй команду qemu-system-i386 -kernel kernel .
Настраиваем GRUB и запускаем ядро
GRUB требует, чтобы название файла с ядром следовало конвенции kernel-<версия> . Так что переименовываем файл - я назову свой kernel-701 .
Теперь кладем ядро в каталог /boot . На это понадобятся привилегии суперпользователя.
В конфигурационный файл GRUB grub.cfg нужно будет добавить что-то в таком роде:
Title myKernel root (hd0,0) kernel /boot/kernel-701 ro
Не забудь убрать директиву hiddenmenu, если она прописана.
GRUB 2
Чтобы запустить созданное нами ядро в GRUB 2, который по умолчанию поставляется в новых дистрибутивах, твой конфиг должен выглядеть следующим образом:
Menuentry "kernel 701" { set root="hd0,msdos1" multiboot /boot/kernel-701 ro }
Благодарю Рубена Лагуану за это дополнение.
Перезагружай компьютер, и ты должен будешь увидеть свое ядро в списке! А выбрав его, ты увидишь ту самую строку.

Это и есть твое ядро!
Пишем ядро с поддержкой клавиатуры и экрана
Мы закончили работу над минимальным ядром, которое загружается через GRUB, работает в защищенном режиме и выводит на экран одну строку. Настала пора расширить его и добавить драйвер клавиатуры, который будет читать символы с клавиатуры и выводить их на экран.
Мы будем общаться с устройствами ввода-вывода через порты ввода-вывода. По сути, они просто адреса на шине ввода-вывода. Для операций чтения и записи в них существуют специальные процессорные инструкции.
Работа с портами: чтение и вывод
read_port: mov edx, in al, dx ret write_port: mov edx, mov al, out dx, al retДоступ к портам ввода-вывода осуществляется при помощи инструкций in и out , входящих в набор x86.
В read_port номер порта передается в качестве аргумента. Когда компилятор вызывает функцию, он кладет все аргументы в стек. Аргумент копируется в регистр edx при помощи указателя на стек. Регистр dx - это нижние 16 бит регистра edx . Инструкция in здесь читает порт, номер которого задан в dx , и кладет результат в al . Регистр al - это нижние 8 бит регистра eax . Возможно, ты помнишь из институтского курса, что значения, возвращаемые функциями, передаются через регистр eax . Таким образом, read_port позволяет нам читать из портов ввода-вывода.
Функция write_port работает схожим образом. Мы принимаем два аргумента: номер порта и данные, которые будут записаны. Инструкция out пишет данные в порт.
Прерывания
Теперь, прежде чем мы вернемся к написанию драйвера, нам нужно понять, как процессор узнает, что какое-то из устройств выполнило операцию.
Самое простое решение - это опрашивать устройства - непрерывно по кругу проверять их статус. Это по очевидным причинам неэффективно и непрактично. Поэтому здесь в игру вступают прерывания. Прерывание - это сигнал, посылаемый процессору устройством или программой, который означает, что произошло событие. Используя прерывания, мы можем избежать необходимости опрашивать устройства и будем реагировать только на интересующие нас события.
За прерывания в архитектуре x86 отвечает чип под названием Programmable Interrupt Controller (PIC). Он обрабатывает хардверные прерывания и направляет и превращает их в соответствующие системные прерывания.
Когда пользователь что-то делает с устройством, чипу PIC отправляется импульс, называемый запросом на прерывание (Interrupt Request, IRQ). PIC переводит полученное прерывание в системное прерывание и отправляет процессору сообщение о том, что пора остановить то, что он делает. Дальнейшая обработка прерываний - это задача ядра.
Без PIC нам бы пришлось опрашивать все устройства, присутствующие в системе, чтобы посмотреть, не произошло ли событие с участием какого-то из них.
Давай разберем, как это работает в случае с клавиатурой. Клавиатура висит на портах 0x60 и 0x64. Порт 0x60 отдает данные (когда нажата какая-то кнопка), а порт 0x64 передает статус. Однако нам нужно знать, когда конкретно читать эти порты.
Прерывания здесь приходятся как нельзя более кстати. Когда кнопка нажата, клавиатура отправляет PIC сигнал по линии прерываний IRQ1. PIС хранит значение offset , сохраненное во время его инициализации. Он добавляет номер входной линии к этому отступу, чтобы сформировать вектор прерывания. Затем процессор ищет структуру данных, называемую «таблица векторов прерываний» (Interrupt Descriptor Table, IDT), чтобы дать функции - обработчику прерывания адрес, соответствующий его номеру.
Затем код по этому адресу исполняется и обрабатывает прерывание.
Задаем IDT
struct IDT_entry{ unsigned short int offset_lowerbits; unsigned short int selector; unsigned char zero; unsigned char type_attr; unsigned short int offset_higherbits; }; struct IDT_entry IDT; void idt_init(void) { unsigned long keyboard_address; unsigned long idt_address; unsigned long idt_ptr; keyboard_address = (unsigned long)keyboard_handler; IDT.offset_lowerbits = keyboard_address & 0xffff; IDT.selector = 0x08; /* KERNEL_CODE_SEGMENT_OFFSET */ IDT.zero = 0; IDT.type_attr = 0x8e; /* INTERRUPT_GATE */ IDT.offset_higherbits = (keyboard_address & 0xffff0000) >> 16; write_port(0x20 , 0x11); write_port(0xA0 , 0x11); write_port(0x21 , 0x20); write_port(0xA1 , 0x28); write_port(0x21 , 0x00); write_port(0xA1 , 0x00); write_port(0x21 , 0x01); write_port(0xA1 , 0x01); write_port(0x21 , 0xff); write_port(0xA1 , 0xff); idt_address = (unsigned long)IDT ; idt_ptr = (sizeof (struct IDT_entry) * IDT_SIZE) + ((idt_address & 0xffff) << 16); idt_ptr = idt_address >> 16 ; load_idt(idt_ptr); }IDT - это массив, объединяющий структуры IDT_entry. Мы еще обсудим привязку клавиатурного прерывания к обработчику, а сейчас посмотрим, как работает PIC.
Современные системы x86 имеют два чипа PIC, у каждого восемь входных линий. Будем называть их PIC1 и PIC2. PIC1 получает от IRQ0 до IRQ7, а PIC2 - от IRQ8 до IRQ15. PIC1 использует порт 0x20 для команд и 0x21 для данных, а PIC2 - порт 0xA0 для команд и 0xA1 для данных.
Оба PIC инициализируются восьмибитными словами, которые называются «командные слова инициализации» (Initialization command words, ICW).
В защищенном режиме обоим PIC первым делом нужно отдать команду инициализации ICW1 (0x11). Она сообщает PIC, что нужно ждать еще трех инициализационных слов, которые придут на порт данных.
Эти команды передадут PIC:
- вектор отступа (ICW2),
- какие между PIC отношения master/slave (ICW3),
- дополнительную информацию об окружении (ICW4).
Вторая команда инициализации (ICW2) тоже шлется на вход каждого PIC. Она назначает offset , то есть значение, к которому мы добавляем номер линии, чтобы получить номер прерывания.
PIC разрешают каскадное перенаправление их выводов на вводы друг друга. Это делается при помощи ICW3, и каждый бит представляет каскадный статус для соответствующего IRQ. Сейчас мы не будем использовать каскадное перенаправление и выставим нули.
ICW4 задает дополнительные параметры окружения. Нам нужно определить только нижний бит, чтобы PIC знали, что мы работаем в режиме 80x86.
Та-дам! Теперь PIC проинициализированы.
У каждого PIC есть внутренний восьмибитный регистр, который называется «регистр масок прерываний» (Interrupt Mask Register, IMR). В нем хранится битовая карта линий IRQ, которые идут в PIC. Если бит задан, PIC игнорирует запрос. Это значит, что мы можем включить или выключить определенную линию IRQ, выставив соответствующее значение в 0 или 1.
Чтение из порта данных возвращает значение в регистре IMR, а запись - меняет регистр. В нашем коде после инициализации PIC мы выставляем все биты в единицу, чем деактивируем все линии IRQ. Позднее мы активируем линии, которые соответствуют клавиатурным прерываниям. Но для начала все же выключим!
Если линии IRQ работают, наши PIC могут получать сигналы по IRQ и преобразовывать их в номер прерывания, добавляя офсет. Нам же нужно заполнить IDT таким образом, чтобы номер прерывания, пришедшего с клавиатуры, соответствовал адресу функции-обработчика, которую мы напишем.
На какой номер прерывания нам нужно завязать в IDT обработчик клавиатуры?
Клавиатура использует IRQ1. Это входная линия 1, ее обрабатывает PIC1. Мы проинициализировали PIC1 с офсетом 0x20 (см. ICW2). Чтобы получить номер прерывания, нужно сложить 1 и 0x20, получится 0x21. Значит, адрес обработчика клавиатуры будет завязан в IDT на прерывание 0x21.
Задача сводится к тому, чтобы заполнить IDT для прерывания 0x21. Мы замапим это прерывание на функцию keyboard_handler , которую напишем в ассемблерном файле.
Каждая запись в IDT состоит из 64 бит. В записи, соответствующей прерыванию, мы не сохраняем адрес функции-обработчика целиком. Вместо этого мы разбиваем его на две части по 16 бит. Нижние биты сохраняются в первых 16 битах записи в IDT, а старшие 16 бит - в последних 16 битах записи. Все это сделано для совместимости с 286-ми процессорами. Как видишь, Intel выделывает такие номера на регулярной основе и во многих-многих местах!
В записи IDT нам осталось прописать тип, обозначив таким образом, что все это делается, чтобы отловить прерывание. Еще нам нужно задать офсет сегмента кода ядра. GRUB задает GDT за нас. Каждая запись GDT имеет длину 8 байт, где дескриптор кода ядра - это второй сегмент, так что его офсет составит 0x08 (подробности не влезут в эту статью). Гейт прерывания представлен как 0x8e. Оставшиеся в середине 8 бит заполняем нулями. Таким образом, мы заполним запись IDT, которая соответствует клавиатурному прерыванию.
Когда с маппингом IDT будет покончено, нам надо будет сообщить процессору, где находится IDT. Для этого существует ассемблерная инструкция lidt, она принимает один операнд. Им служит указатель на дескриптор структуры, которая описывает IDT.
С дескриптором никаких сложностей. Он содержит размер IDT в байтах и его адрес. Я использовал массив, чтобы вышло компактнее. Точно так же можно заполнить дескриптор при помощи структуры.
В переменной idr_ptr у нас есть указатель, который мы передаем инструкции lidt в функции load_idt() .
Load_idt: mov edx, lidt sti ret
Дополнительно функция load_idt() возвращает прерывание при использовании инструкции sti .
Заполнив и загрузив IDT, мы можем обратиться к IRQ клавиатуры, используя маску прерывания, о которой мы говорили ранее.
Void kb_init(void) { write_port(0x21 , 0xFD); }
0xFD - это 11111101 - включаем только IRQ1 (клавиатуру).
Функция - обработчик прерывания клавиатуры
Итак, мы успешно привязали прерывания клавиатуры к функции keyboard_handler , создав запись IDT для прерывания 0x21. Эта функция будет вызываться каждый раз, когда ты нажимаешь на какую-нибудь кнопку.
Keyboard_handler: call keyboard_handler_main iretd
Эта функция вызывает другую функцию, написанную на C, и возвращает управление при помощи инструкций класса iret. Мы могли бы тут написать весь наш обработчик, но на C кодить значительно легче, так что перекатываемся туда. Инструкции iret/iretd нужно использовать вместо ret , когда управление возвращается из функции, обрабатывающей прерывание, в программу, выполнение которой было им прервано. Этот класс инструкций поднимает флаговый регистр, который попадает в стек при вызове прерывания.
Void keyboard_handler_main(void) { unsigned char status; char keycode; /* Пишем EOI */ write_port(0x20, 0x20); status = read_port(KEYBOARD_STATUS_PORT); /* Нижний бит статуса будет выставлен, если буфер не пуст */ if (status & 0x01) { keycode = read_port(KEYBOARD_DATA_PORT); if(keycode < 0) return; vidptr = keyboard_map; vidptr = 0x07; } }
Здесь мы сначала даем сигнал EOI (End Of Interrupt, окончание обработки прерывания), записав его в командный порт PIC. Только после этого PIC разрешит дальнейшие запросы на прерывание. Нам нужно читать два порта: порт данных 0x60 и порт команд (он же status port) 0x64.
Первым делом читаем порт 0x64, чтобы получить статус. Если нижний бит статуса - это ноль, значит, буфер пуст и данных для чтения нет. В других случаях мы можем читать порт данных 0x60. Он будет выдавать нам код нажатой клавиши. Каждый код соответствует одной кнопке. Мы используем простой массив символов, заданный в файле keyboard_map.h , чтобы привязать коды к соответствующим символам. Затем символ выводится на экран при помощи той же техники, что мы применяли в первой версии ядра.
Чтобы не усложнять код, я здесь обрабатываю только строчные буквы от a до z и цифры от 0 до 9. Ты с легкостью можешь добавить спецсимволы, Alt, Shift и Caps Lock. Узнать, что клавиша была нажата или отпущена, можно из вывода командного порта и выполнять соответствующее действие. Точно так же можешь привязать любые сочетания клавиш к специальным функциям вроде выключения.
Теперь ты можешь собрать ядро, запустить его на реальной машине или на эмуляторе (QEMU) так же, как и в первой части.