Grep регулярные выражения примеры. Регулярные выражения Bash: руководство по созданию, применение, примеры
Для того, чтобы полноценно обрабатывать тексты в bash-скриптах с помощью sed и awk, просто необходимо разобраться с регулярными выражениями. Реализации этого полезнейшего инструмента можно найти буквально повсюду, и хотя устроены все регулярные выражения схожим образом, основаны на одних и тех же идеях, в разных средах работа с ними имеет определённые особенности. Тут мы поговорим о регулярных выражениях, которые подходят для использования в сценариях командной строки Linux.
Этот материал задуман как введение в регулярные выражения, рассчитанное на тех, кто может совершенно не знать о том, что это такое. Поэтому начнём с самого начала.
Что такое регулярные выражения
У многих, когда они впервые видят регулярные выражения, сразу же возникает мысль, что перед ними бессмысленное нагромождение символов. Но это, конечно, далеко не так. Взгляните, например, на это регулярное выражение
На наш взгляд даже абсолютный новичок сходу поймёт, как оно устроено и зачем нужно:) Если же вам не вполне понятно - просто читайте дальше и всё встанет на свои места.
Регулярное выражение - это шаблон, пользуясь которым программы вроде sed или awk фильтруют тексты. В шаблонах используются обычные ASCII-символы, представляющие сами себя, и так называемые метасимволы, которые играют особую роль, например, позволяя ссылаться на некие группы символов.
Типы регулярных выражений
Реализации регулярных выражений в различных средах, например, в языках программирования вроде Java, Perl и Python, в инструментах Linux вроде sed, awk и grep, имеют определённые особенности. Эти особенности зависят от так называемых движков обработки регулярных выражений, которые занимаются интерпретацией шаблонов.В Linux имеется два движка регулярных выражений:
- Движок, поддерживающий стандарт POSIX Basic Regular Expression (BRE).
- Движок, поддерживающий стандарт POSIX Extended Regular Expression (ERE).
Стандарт POSIX ERE часто реализуют в языках программирования. Он позволяет пользоваться большим количеством средств при разработке регулярных выражений. Например, это могут быть специальные последовательности символов для часто используемых шаблонов, вроде поиска в тексте отдельных слов или наборов цифр. Awk поддерживает стандарт ERE.
Существует много способов разработки регулярных выражений, зависящих и от мнения программиста, и от особенностей движка, под который их создают. Непросто писать универсальные регулярные выражения, которые сможет понять любой движок. Поэтому мы сосредоточимся на наиболее часто используемых регулярных выражениях и рассмотрим особенности их реализации для sed и awk.
Регулярные выражения POSIX BRE
Пожалуй, самый простой шаблон BRE представляет собой регулярное выражение для поиска точного вхождения последовательности символов в тексте. Вот как выглядит поиск строки в sed и awk: $ echo "This is a test" | sed -n "/test/p"
$ echo "This is a test" | awk "/test/{print $0}"
Поиск текста по шаблону в sed
Поиск текста по шаблону в awk
Можно заметить, что поиск заданного шаблона выполняется без учёта точного места нахождения текста в строке. Кроме того, не имеет значение и количество вхождений. После того, как регулярное выражение найдёт заданный текст в любом месте строки, строка считается подходящей и передаётся для дальнейшей обработки.
Работая с регулярными выражениями нужно учитывать то, что они чувствительны к регистру символов:
$ echo "This is a test" | awk "/Test/{print $0}"
$ echo "This is a test" | awk "/test/{print $0}"
Регулярные выражения чувствительны к регистру
Первое регулярное выражение совпадений не нашло, так как слово «test», начинающееся с заглавной буквы, в тексте не встречается. Второе же, настроенное на поиск слова, написанного прописными буквами, обнаружило в потоке подходящую строку.
В регулярных выражениях можно использовать не только буквы, но и пробелы, и цифры:
$ echo "This is a test 2 again" | awk "/test 2/{print $0}"
Поиск фрагмента текста, содержащего пробелы и цифры
Пробелы воспринимаются движком регулярных выражений как обычные символы.
Специальные символы
При использовании различных символов в регулярных выражениях надо учитывать некоторые особенности. Так, существуют некоторые специальные символы, или метасимволы, использование которых в шаблоне требует особого подхода. Вот они: .*^${}\+?|()
Если один из них нужен в шаблоне, его нужно будет экранировать с помощью обратной косой черты (обратного слэша) - \ .
Например, если в тексте нужно найти знак доллара, его надо включить в шаблон, предварив символом экранирования. Скажем, имеется файл myfile с таким текстом:
There is 10$ on my pocket
Знак доллара можно обнаружить с помощью такого шаблона:
$ awk "/\$/{print $0}" myfile
Использование в шаблоне специального символа
Кроме того, обратная косая черта - это тоже специальный символ, поэтому, если нужно использовать его в шаблоне, его тоже надо будет экранировать. Выглядит это как два слэша, идущих друг за другом:
$ echo "\ is a special character" | awk "/\\/{print $0}"
Экранирование обратного слэша
Хотя прямой слэш и не входит в приведённый выше список специальных символов, попытка воспользоваться им в регулярном выражении, написанном для sed или awk, приведёт к ошибке:
$ echo "3 / 2" | awk "///{print $0}"
Неправильное использование прямого слэша в шаблоне
Если он нужен, его тоже надо экранировать:
$ echo "3 / 2" | awk "/\//{print $0}"
Экранирование прямого слэша
Якорные символы
Существуют два специальных символа для привязки шаблона к началу или к концу текстовой строки. Символ «крышка» - ^ позволяет описывать последовательности символов, которые находятся в начале текстовых строк. Если искомый шаблон окажется в другом месте строки, регулярное выражение на него не отреагирует. Выглядит использование этого символа так: $ echo "welcome to likegeeks website" | awk "/^likegeeks/{print $0}"
$ echo "likegeeks website" | awk "/^likegeeks/{print $0}"
Поиск шаблона в начале строки
Символ ^ предназначен для поиска шаблона в начале строки, при этом регистр символов так же учитывается. Посмотрим, как это отразится на обработке текстового файла:
$ awk "/^this/{print $0}" myfile

Поиск шаблона в начале строки в тексте из файла
При использовании sed, если поместить крышку где-нибудь внутри шаблона, она будет восприниматься как любой другой обычный символ:
$ echo "This ^ is a test" | sed -n "/s ^/p"
Крышка, находящаяся не в начале шаблона в sed
В awk, при использовании такого же шаблона, данный символ надо экранировать:
$ echo "This ^ is a test" | awk "/s \^/{print $0}"
Крышка, находящаяся не в начале шаблона в awk
С поиском фрагментов текста, находящихся в начале строки мы разобрались. Что, если надо найти нечто, расположенное в конце строки?
В этом нам поможет знак доллара - $ , являющийся якорным символом конца строки:
$ echo "This is a test" | awk "/test$/{print $0}"
Поиск текста, находящегося в конце строки
В одном и том же шаблоне можно использовать оба якорных символа. Выполним обработку файла myfile , содержимое которого показано на рисунке ниже, с помощью такого регулярного выражения:
$ awk "/^this is a test$/{print $0}" myfile

Шаблон, в котором использованы специальные символы начала и конца строки
Как видно, шаблон среагировал лишь на строку, полностью соответствующую заданной последовательности символов и их расположению.
Вот как, пользуясь якорными символами, отфильтровать пустые строки:
$ awk "!/^$/{print $0}" myfile
В данном шаблоне использовал символ отрицания, восклицательный знак - ! . Благодаря использованию такого шаблона выполняется поиск строк, не содержащих ничего между началом и концом строки, а благодаря восклицательному знаку на печать выводятся лишь строки, которые не соответствуют этому шаблону.
Символ «точка»
Точка используется для поиска любого одиночного символа, за исключением символа перевода строки. Передадим такому регулярному выражению файл myfile , содержимое которого приведено ниже: $ awk "/.st/{print $0}" myfile

Использование точки в регулярных выражениях
Как видно по выведенным данным, шаблону соответствуют лишь первые две строки из файла, так как они содержат последовательность символов «st», предварённую ещё одним символом, в то время как третья строка подходящей последовательности не содержит, а в четвёртой она есть, но находится в самом начале строки.
Классы символов
Точка соответствует любому одиночному символу, но что если нужно более гибко ограничить набор искомых символов? В подобной ситуации можно воспользоваться классами символов.Благодаря такому подходу можно организовать поиск любого символа из заданного набора. Для описания класса символов используются квадратные скобки - :
$ awk "/th/{print $0}" myfile

Описание класса символов в регулярном выражении
Тут мы ищем последовательность символов «th», перед которой есть символ «o» или символ «i».
Классы оказываются очень кстати, если выполняется поиск слов, которые могут начинаться как с прописной, так и со строчной буквы:
$ echo "this is a test" | awk "/his is a test/{print $0}"
$ echo "This is a test" | awk "/his is a test/{print $0}"
Поиск слов, которые могут начинаться со строчной или прописной буквы
Классы символов не ограничены буквами. Тут можно использовать и другие символы. Нельзя заранее сказать, в какой ситуации понадобятся классы - всё зависит от решаемой задачи.
Отрицание классов символов
Классы символов можно использовать и для решения задачи, обратной описанной выше. А именно, вместо поиска символов, входящих в класс, можно организовать поиск всего, что в класс не входит. Для того, чтобы добиться такого поведения регулярного выражения, перед списком символов класса нужно поместить знак ^ . Выглядит это так: $ awk "/[^oi]th/{print $0}" myfile

Поиск символов, не входящих в класс
В данном случае будут найдены последовательности символов «th», перед которыми нет ни «o», ни «i».
Диапазоны символов
В символьных классах можно описывать диапазоны символов, используя тире: $ awk "/st/{print $0}" myfile

Описание диапазона символов в символьном классе
В данном примере регулярное выражение реагирует на последовательность символов «st», перед которой находится любой символ, расположенный, в алфавитном порядке, между символами «e» и «p».
Диапазоны можно создавать и из чисел:
$ echo "123" | awk "//"
$ echo "12a" | awk "//"
Регулярное выражение для поиска трёх любых чисел
В класс символов могут входить несколько диапазонов:
$ awk "/st/{print $0}" myfile

Класс символов, состоящий из нескольких диапазонов
Данное регулярное выражение найдёт все последовательности «st», перед которыми есть символы из диапазонов a-f и m-z .
Специальные классы символов
В BRE имеются специальные классы символов, которые можно использовать при написании регулярных выражений:- [[:alpha:]] - соответствует любому алфавитному символу, записанному в верхнем или нижнем регистре.
- [[:alnum:]] - соответствует любому алфавитно-цифровому символу, а именно - символам в диапазонах 0-9 , A-Z , a-z .
- [[:blank:]] - соответствует пробелу и знаку табуляции.
- [[:digit:]] - любой цифровой символ от 0 до 9 .
- [[:upper:]] - алфавитные символы в верхнем регистре - A-Z .
- [[:lower:]] - алфавитные символы в нижнем регистре - a-z .
- [[:print:]] - соответствует любому печатаемому символу.
- [[:punct:]] - соответствует знакам препинания.
- [[:space:]] - пробельные символы, в частности - пробел, знак табуляции, символы NL , FF , VT , CR .
$ echo "abc" | awk "/[[:alpha:]]/{print $0}"
$ echo "abc" | awk "/[[:digit:]]/{print $0}"
$ echo "abc123" | awk "/[[:digit:]]/{print $0}"

Специальные классы символов в регулярных выражениях
Символ «звёздочка»
Если в шаблоне после символа поместить звёздочку, это будет означать, что регулярное выражение сработает, если символ появляется в строке любое количество раз - включая и ситуацию, когда символ в строке отсутствует. $ echo "test" | awk "/tes*t/{print $0}"
$ echo "tessst" | awk "/tes*t/{print $0}"

Использование символа * в регулярных выражениях
Этот шаблонный символ обычно используют для работы со словами, в которых постоянно встречаются опечатки, или для слов, допускающих разные варианты корректного написания:
$ echo "I like green color" | awk "/colou*r/{print $0}"
$ echo "I like green colour " | awk "/colou*r/{print $0}"
Поиск слова, имеющего разные варианты написания
В этом примере одно и то же регулярное выражение реагирует и на слово «color», и на слово «colour». Это так благодаря тому, что символ «u», после которого стоит звёздочка, может либо отсутствовать, либо встречаться несколько раз подряд.
Ещё одна полезная возможность, вытекающая из особенностей символа звёздочки, заключается в комбинировании его с точкой. Такая комбинация позволяет регулярному выражению реагировать на любое количество любых символов:
$ awk "/this.*test/{print $0}" myfile

Шаблон, реагирующий на любое количество любых символов
В данном случае неважно сколько и каких символов находится между словами «this» и «test».
Звёздочку можно использовать и с классами символов:
$ echo "st" | awk "/s*t/{print $0}"
$ echo "sat" | awk "/s*t/{print $0}"
$ echo "set" | awk "/s*t/{print $0}"

Использование звёздочки с классами символов
Во всех трёх примерах регулярное выражение срабатывает, так как звёздочка после класса символов означает, что если будет найдено любое количество символов «a» или «e», а также если их найти не удастся, строка будет соответствовать заданному шаблону.
Регулярные выражения POSIX ERE
Шаблоны стандарта POSIX ERE, которые поддерживают некоторые утилиты Linux, могут содержать дополнительные символы. Как уже было сказано, awk поддерживает этот стандарт, а вот sed - нет.Тут мы рассмотрим наиболее часто используемые в ERE-шаблонах символы, которые пригодятся вам при создании собственных регулярных выражений.
▍Вопросительный знак
Вопросительный знак указывает на то, что предшествующий символ может встретиться в тексте один раз или не встретиться вовсе. Этот символ - один из метасимволов повторений. Вот несколько примеров: $ echo "tet" | awk "/tes?t/{print $0}"
$ echo "test" | awk "/tes?t/{print $0}"
$ echo "tesst" | awk "/tes?t/{print $0}"

Вопросительный знак в регулярных выражениях
Как видно, в третьем случае буква «s» встречается дважды, поэтому на слово «tesst» регулярное выражение не реагирует.
Вопросительный знак можно использовать и с классами символов:
$ echo "tst" | awk "/t?st/{print $0}"
$ echo "test" | awk "/t?st/{print $0}"
$ echo "tast" | awk "/t?st/{print $0}"
$ echo "taest" | awk "/t?st/{print $0}"
$ echo "teest" | awk "/t?st/{print $0}"

Вопросительный знак и классы символов
Если символов из класса в строке нет, или один из них встречается один раз, регулярное выражение срабатывает, однако стоит в слове появиться двум символам и система уже не находит в тексте соответствия шаблону.
▍Символ «плюс»
Символ «плюс» в шаблоне указывает на то, что регулярное выражение обнаружит искомое в том случае, если предшествующий символ встретится в тексте один или более раз. При этом на отсутствие символа такая конструкция реагировать не будет: $ echo "test" | awk "/te+st/{print $0}"
$ echo "teest" | awk "/te+st/{print $0}"
$ echo "tst" | awk "/te+st/{print $0}"

Символ «плюс» в регулярных выражениях
В данном примере, если символа «e» в слове нет, движок регулярных выражений не найдёт в тексте соответствий шаблону. Символ «плюс» работает и с классами символов - этим он похож на звёздочку и вопросительный знак:
$ echo "tst" | awk "/t+st/{print $0}"
$ echo "test" | awk "/t+st/{print $0}"
$ echo "teast" | awk "/t+st/{print $0}"
$ echo "teeast" | awk "/t+st/{print $0}"

Знак «плюс» и классы символов
В данном случае если в строке имеется любой символ из класса, текст будет сочтён соответствующим шаблону.
▍Фигурные скобки
Фигурные скобки, которыми можно пользоваться в ERE-шаблонах, похожи на символы, рассмотренные выше, но они позволяют точнее задавать необходимое число вхождений предшествующего им символа. Указывать ограничение можно в двух форматах:- n - число, задающее точное число искомых вхождений
- n, m - два числа, которые трактуются так: «как минимум n раз, но не больше чем m».
$ echo "tst" | awk "/te{1}st/{print $0}"
$ echo "test" | awk "/te{1}st/{print $0}"
Фигурные скобки в шаблонах, поиск точного числа вхождений
В старых версиях awk нужно было использовать ключ командной строки --re-interval для того, чтобы программа распознавала интервалы в регулярных выражениях, но в новых версиях этого делать не нужно.
$ echo "tst" | awk "/te{1,2}st/{print $0}"
$ echo "test" | awk "/te{1,2}st/{print $0}"
$ echo "teest" | awk "/te{1,2}st/{print $0}"
$ echo "teeest" | awk "/te{1,2}st/{print $0}"

Интервал, заданный в фигурных скобках
В данном примере символ «e» должен встретиться в строке 1 или 2 раза, тогда регулярное выражение отреагирует на текст.
Фигурные скобки можно применять и с классами символов. Тут действуют уже знакомые вам принципы:
$ echo "tst" | awk "/t{1,2}st/{print $0}"
$ echo "test" | awk "/t{1,2}st/{print $0}"
$ echo "teest" | awk "/t{1,2}st/{print $0}"
$ echo "teeast" | awk "/t{1,2}st/{print $0}"

Фигурные скобки и классы символов
Шаблон отреагирует на текст в том случае, если в нём один или два раза встретится символ «a» или символ «e».
▍Символ логического «или»
Символ | - вертикальная черта, означает в регулярных выражениях логическое «или». Обрабатывая регулярное выражение, содержащее несколько фрагментов, разделённых таким знаком, движок сочтёт анализируемый текст подходящим в том случае, если он будет соответствовать любому из фрагментов. Вот пример: $ echo "This is a test" | awk "/test|exam/{print $0}"
$ echo "This is an exam" | awk "/test|exam/{print $0}"
$ echo "This is something else" | awk "/test|exam/{print $0}"

Логическое «или» в регулярных выражениях
В данном примере регулярное выражение настроено на поиск в тексте слов «test» или «exam». Обратите внимание на то, что между фрагментами шаблона и разделяющим их символом | не должно быть пробелов.
Фрагменты регулярных выражений можно группировать, пользуясь круглыми скобками. Если сгруппировать некую последовательность символов, она будет восприниматься системой как обычный символ. То есть, например, к ней можно будет применить метасимволы повторений. Вот как это выглядит: $ echo "Like" | awk "/Like(Geeks)?/{print $0}"
$ echo "LikeGeeks" | awk "/Like(Geeks)?/{print $0}"

Группировка фрагментов регулярных выражений
В данных примерах слово «Geeks» заключено в круглые скобки, после этой конструкции идёт знак вопроса. Напомним, что вопросительный знак означает «0 или 1 повторение», в результате регулярное выражение отреагирует и на строку «Like», и на строку «LikeGeeks».
Практические примеры
После того, как мы разобрали основы регулярных выражений, пришло время сделать с их помощью что-нибудь полезное.▍Подсчёт количества файлов
Напишем bash-скрипт, который подсчитывает файлы, находящиеся в директориях, которые записаны в переменную окружения PATH . Для того, чтобы это сделать, понадобится, для начала, сформировать список путей к директориям. Сделаем это с помощью sed, заменив двоеточия на пробелы: $ echo $PATH | sed "s/:/ /g"
Команда замены поддерживает регулярные выражения в качестве шаблонов для поиска текста. В данном случае всё предельно просто, ищем мы символ двоеточия, но никто не мешает использовать здесь и что-нибудь другое - всё зависит от конкретной задачи.
Теперь надо пройтись по полученному списку в цикле и выполнить там необходимые для подсчёта количества файлов действия. Общая схема скрипта будет такой:
Mypath=$(echo $PATH | sed "s/:/ /g")
for directory in $mypath
do
done
Теперь напишем полный текст скрипта, воспользовавшись командой ls для получения сведений о количестве файлов в каждой из директорий:
#!/bin/bash
mypath=$(echo $PATH | sed "s/:/ /g")
count=0
for directory in $mypath
do
check=$(ls $directory)
for item in $check
do
count=$[ $count + 1 ]
done
echo "$directory - $count"
count=0
done
При запуске скрипта может оказаться, что некоторых директорий из PATH не существует, однако, это не помешает ему посчитать файлы в существующих директориях.

Подсчёт файлов
Главная ценность этого примера заключается в том, что пользуясь тем же подходом, можно решать и куда более сложные задачи. Какие именно - зависит от ваших потребностей.
▍Проверка адресов электронной почты
Существуют веб-сайты с огромными коллекциями регулярных выражений, которые позволяют проверять адреса электронной почты, телефонные номера, и так далее. Однако, одно дело - взять готовое, и совсем другое - создать что-то самому. Поэтому напишем регулярное выражение для проверки адресов электронной почты. Начнём с анализа исходных данных. Вот, например, некий адрес:[email protected]
Имя пользователя, username , может состоять из алфавитно-цифровых и некоторых других символов. А именно, это точка, тире, символ подчёркивания, знак «плюс». За именем пользователя следует знак @.
Вооружившись этими знаниями, начнём сборку регулярного выражения с его левой части, которая служит для проверки имени пользователя. Вот что у нас получилось:
^(+)@
Это регулярное выражение можно прочитать так: «В начале строки должен быть как минимум один символ из тех, которые имеются в группе, заданной в квадратных скобках, а после этого должен идти знак @».
Теперь - очередь имени хоста - hostname . Тут применимы те же правила, что и для имени пользователя, поэтому шаблон для него будет выглядеть так:
(+)
Имя домена верхнего уровня подчиняется особым правилам. Тут могут быть лишь алфавитные символы, которых должно быть не меньше двух (например, такие домены обычно содержат код страны), и не больше пяти. Всё это значит, что шаблон для проверки последней части адреса будет таким:
\.({2,5})$
Прочесть его можно так: «Сначала должна быть точка, потом - от 2 до 5 алфавитных символов, а после этого строка заканчивается».
Подготовив шаблоны для отдельных частей регулярного выражения, соберём их вместе:
^(+)@(+)\.({2,5})$
Теперь осталось лишь протестировать то, что получилось:
$ echo "[email protected]" | awk "/^(+)@(+)\.({2,5})$/{print $0}"
$ echo "[email protected]" | awk "/^(+)@(+)\.({2,5})$/{print $0}"

Проверка адреса электронной почты с помощью регулярных выражений
То, что переданный awk текст выводится на экран, означает, что система распознала в нём адрес электронной почты.
Итоги
Если регулярное выражение для проверки адресов электронной почты, которое встретилось вам в самом начале статьи, казалось тогда совершенно непонятным, надеемся, сейчас оно уже не выглядит бессмысленным набором символов. Если это действительно так - значит данный материал выполнил своё предназначение. На самом деле, регулярные выражения - это тема, которой можно заниматься всю жизнь, но даже то немногое, что мы разобрали, уже способно помочь вам в написании скриптов, которые довольно продвинуто обрабатывают тексты.В этой серии материалов мы обычно показывали очень простые примеры bash-скриптов, которые состояли буквально из нескольких строк. В следующий раз рассмотрим кое-что более масштабное.
Уважаемые читатели! А вы пользуетесь регулярными выражениями при обработке текстов в сценариях командной строки?
Для того, чтобы полноценно обрабатывать тексты в bash-скриптах с помощью sed и awk, просто необходимо разобраться с регулярными выражениями. Реализации этого полезнейшего инструмента можно найти буквально повсюду, и хотя устроены все регулярные выражения схожим образом, основаны на одних и тех же идеях, в разных средах работа с ними имеет определённые особенности. Тут мы поговорим о регулярных выражениях, которые подходят для использования в сценариях командной строки Linux.
Этот материал задуман как введение в регулярные выражения, рассчитанное на тех, кто может совершенно не знать о том, что это такое. Поэтому начнём с самого начала.
Что такое регулярные выражения
У многих, когда они впервые видят регулярные выражения, сразу же возникает мысль, что перед ними бессмысленное нагромождение символов. Но это, конечно, далеко не так. Взгляните, например, на это регулярное выражение
На наш взгляд даже абсолютный новичок сходу поймёт, как оно устроено и зачем нужно:) Если же вам не вполне понятно - просто читайте дальше и всё встанет на свои места.
Регулярное выражение - это шаблон, пользуясь которым программы вроде sed или awk фильтруют тексты. В шаблонах используются обычные ASCII-символы, представляющие сами себя, и так называемые метасимволы, которые играют особую роль, например, позволяя ссылаться на некие группы символов.
Типы регулярных выражений
Реализации регулярных выражений в различных средах, например, в языках программирования вроде Java, Perl и Python, в инструментах Linux вроде sed, awk и grep, имеют определённые особенности. Эти особенности зависят от так называемых движков обработки регулярных выражений, которые занимаются интерпретацией шаблонов.
В Linux имеется два движка регулярных выражений:
- Движок, поддерживающий стандарт POSIX Basic Regular Expression (BRE).
- Движок, поддерживающий стандарт POSIX Extended Regular Expression (ERE).
Большинство утилит Linux соответствуют, как минимум, стандарту POSIX BRE, но некоторые утилиты (в их числе - sed) понимают лишь некое подмножество стандарта BRE. Одна из причин такого ограничения - стремление сделать такие утилиты как можно более быстрыми в деле обработки текстов.
Стандарт POSIX ERE часто реализуют в языках программирования. Он позволяет пользоваться большим количеством средств при разработке регулярных выражений. Например, это могут быть специальные последовательности символов для часто используемых шаблонов, вроде поиска в тексте отдельных слов или наборов цифр. Awk поддерживает стандарт ERE.
Существует много способов разработки регулярных выражений, зависящих и от мнения программиста, и от особенностей движка, под который их создают. Непросто писать универсальные регулярные выражения, которые сможет понять любой движок. Поэтому мы сосредоточимся на наиболее часто используемых регулярных выражениях и рассмотрим особенности их реализации для sed и awk.
Регулярные выражения POSIX BRE
Пожалуй, самый простой шаблон BRE представляет собой регулярное выражение для поиска точного вхождения последовательности символов в тексте. Вот как выглядит поиск строки в sed и awk:
$ echo "This is a test" | sed -n "/test/p" $ echo "This is a test" | awk "/test/{print $0}"
Поиск текста по шаблону в sed
Поиск текста по шаблону в awk
Можно заметить, что поиск заданного шаблона выполняется без учёта точного места нахождения текста в строке. Кроме того, не имеет значение и количество вхождений. После того, как регулярное выражение найдёт заданный текст в любом месте строки, строка считается подходящей и передаётся для дальнейшей обработки.
Работая с регулярными выражениями нужно учитывать то, что они чувствительны к регистру символов:
$ echo "This is a test" | awk "/Test/{print $0}" $ echo "This is a test" | awk "/test/{print $0}"
Регулярные выражения чувствительны к регистру
Первое регулярное выражение совпадений не нашло, так как слово «test», начинающееся с заглавной буквы, в тексте не встречается. Второе же, настроенное на поиск слова, написанного прописными буквами, обнаружило в потоке подходящую строку.
В регулярных выражениях можно использовать не только буквы, но и пробелы, и цифры:
$ echo "This is a test 2 again" | awk "/test 2/{print $0}"
Поиск фрагмента текста, содержащего пробелы и цифры
Пробелы воспринимаются движком регулярных выражений как обычные символы.
Специальные символы
При использовании различных символов в регулярных выражениях надо учитывать некоторые особенности. Так, существуют некоторые специальные символы, или метасимволы, использование которых в шаблоне требует особого подхода. Вот они:
.*^${}+?|()Если один из них нужен в шаблоне, его нужно будет экранировать с помощью обратной косой черты (обратного слэша) - .
Например, если в тексте нужно найти знак доллара, его надо включить в шаблон, предварив символом экранирования. Скажем, имеется файл myfile с таким текстом:
There is 10$ on my pocket
Знак доллара можно обнаружить с помощью такого шаблона:
$ awk "/$/{print $0}" myfile
Использование в шаблоне специального символа
Кроме того, обратная косая черта - это тоже специальный символ, поэтому, если нужно использовать его в шаблоне, его тоже надо будет экранировать. Выглядит это как два слэша, идущих друг за другом:
$ echo " is a special character" | awk "/\/{print $0}"
Экранирование обратного слэша
Хотя прямой слэш и не входит в приведённый выше список специальных символов, попытка воспользоваться им в регулярном выражении, написанном для sed или awk, приведёт к ошибке:
Неправильное использование прямого слэша в шаблоне
Если он нужен, его тоже надо экранировать:
$ echo "3 / 2" | awk "///{print $0}"
Экранирование прямого слэша
Якорные символы
Существуют два специальных символа для привязки шаблона к началу или к концу текстовой строки. Символ «крышка» - ^ позволяет описывать последовательности символов, которые находятся в начале текстовых строк. Если искомый шаблон окажется в другом месте строки, регулярное выражение на него не отреагирует. Выглядит использование этого символа так:
$ echo "welcome to likegeeks website" | awk "/^likegeeks/{print $0}" $ echo "likegeeks website" | awk "/^likegeeks/{print $0}"
Поиск шаблона в начале строки
Символ ^ предназначен для поиска шаблона в начале строки, при этом регистр символов так же учитывается. Посмотрим, как это отразится на обработке текстового файла:
$ awk "/^this/{print $0}" myfile

Поиск шаблона в начале строки в тексте из файла
При использовании sed, если поместить крышку где-нибудь внутри шаблона, она будет восприниматься как любой другой обычный символ:
$ echo "This ^ is a test" | sed -n "/s ^/p"
Крышка, находящаяся не в начале шаблона в sed
В awk, при использовании такого же шаблона, данный символ надо экранировать:
$ echo "This ^ is a test" | awk "/s ^/{print $0}"
Крышка, находящаяся не в начале шаблона в awk
С поиском фрагментов текста, находящихся в начале строки мы разобрались. Что, если надо найти нечто, расположенное в конце строки?
В этом нам поможет знак доллара - $ , являющийся якорным символом конца строки:
$ echo "This is a test" | awk "/test$/{print $0}"
Поиск текста, находящегося в конце строки
В одном и том же шаблоне можно использовать оба якорных символа. Выполним обработку файла myfile , содержимое которого показано на рисунке ниже, с помощью такого регулярного выражения:
$ awk "/^this is a test$/{print $0}" myfile

Шаблон, в котором использованы специальные символы начала и конца строки
Как видно, шаблон среагировал лишь на строку, полностью соответствующую заданной последовательности символов и их расположению.
Вот как, пользуясь якорными символами, отфильтровать пустые строки:
$ awk "!/^$/{print $0}" myfile
В данном шаблоне использовал символ отрицания, восклицательный знак - ! . Благодаря использованию такого шаблона выполняется поиск строк, не содержащих ничего между началом и концом строки, а благодаря восклицательному знаку на печать выводятся лишь строки, которые не соответствуют этому шаблону.
Символ «точка»
Точка используется для поиска любого одиночного символа, за исключением символа перевода строки. Передадим такому регулярному выражению файл myfile , содержимое которого приведено ниже:
$ awk "/.st/{print $0}" myfile

Использование точки в регулярных выражениях
Как видно по выведенным данным, шаблону соответствуют лишь первые две строки из файла, так как они содержат последовательность символов «st», предварённую ещё одним символом, в то время как третья строка подходящей последовательности не содержит, а в четвёртой она есть, но находится в самом начале строки.
Классы символов
Точка соответствует любому одиночному символу, но что если нужно более гибко ограничить набор искомых символов? В подобной ситуации можно воспользоваться классами символов.
Благодаря такому подходу можно организовать поиск любого символа из заданного набора. Для описания класса символов используются квадратные скобки - :
$ awk "/th/{print $0}" myfile

Описание класса символов в регулярном выражении
Тут мы ищем последовательность символов «th», перед которой есть символ «o» или символ «i».
Классы оказываются очень кстати, если выполняется поиск слов, которые могут начинаться как с прописной, так и со строчной буквы:
$ echo "this is a test" | awk "/his is a test/{print $0}" $ echo "This is a test" | awk "/his is a test/{print $0}"
Поиск слов, которые могут начинаться со строчной или прописной буквы
Классы символов не ограничены буквами. Тут можно использовать и другие символы. Нельзя заранее сказать, в какой ситуации понадобятся классы - всё зависит от решаемой задачи.
Отрицание классов символов
Классы символов можно использовать и для решения задачи, обратной описанной выше. А именно, вместо поиска символов, входящих в класс, можно организовать поиск всего, что в класс не входит. Для того, чтобы добиться такого поведения регулярного выражения, перед списком символов класса нужно поместить знак ^ . Выглядит это так:
$ awk "/[^oi]th/{print $0}" myfile

Поиск символов, не входящих в класс
В данном случае будут найдены последовательности символов «th», перед которыми нет ни «o», ни «i».
Диапазоны символов
В символьных классах можно описывать диапазоны символов, используя тире:
$ awk "/st/{print $0}" myfile

Описание диапазона символов в символьном классе
В данном примере регулярное выражение реагирует на последовательность символов «st», перед которой находится любой символ, расположенный, в алфавитном порядке, между символами «e» и «p».
Диапазоны можно создавать и из чисел:
$ echo "123" | awk "//" $ echo "12a" | awk "//"
Регулярное выражение для поиска трёх любых чисел
В класс символов могут входить несколько диапазонов:
$ awk "/st/{print $0}" myfile

Класс символов, состоящий из нескольких диапазонов
Данное регулярное выражение найдёт все последовательности «st», перед которыми есть символы из диапазонов a-f и m-z .
Специальные классы символов
В BRE имеются специальные классы символов, которые можно использовать при написании регулярных выражений:
- [[:alpha:]] - соответствует любому алфавитному символу, записанному в верхнем или нижнем регистре.
- [[:alnum:]] - соответствует любому алфавитно-цифровому символу, а именно - символам в диапазонах 0-9 , A-Z , a-z .
- [[:blank:]] - соответствует пробелу и знаку табуляции.
- [[:digit:]] - любой цифровой символ от 0 до 9 .
- [[:upper:]] - алфавитные символы в верхнем регистре - A-Z .
- [[:lower:]] - алфавитные символы в нижнем регистре - a-z .
- [[:print:]] - соответствует любому печатаемому символу.
- [[:punct:]] - соответствует знакам препинания.
- [[:space:]] - пробельные символы, в частности - пробел, знак табуляции, символы NL , FF , VT , CR .
Использовать специальные классы в шаблонах можно так:
$ echo "abc" | awk "/[[:alpha:]]/{print $0}" $ echo "abc" | awk "/[[:digit:]]/{print $0}" $ echo "abc123" | awk "/[[:digit:]]/{print $0}"

Специальные классы символов в регулярных выражениях
Символ «звёздочка»
Если в шаблоне после символа поместить звёздочку, это будет означать, что регулярное выражение сработает, если символ появляется в строке любое количество раз - включая и ситуацию, когда символ в строке отсутствует.
$ echo "test" | awk "/tes*t/{print $0}" $ echo "tessst" | awk "/tes*t/{print $0}"

Использование символа * в регулярных выражениях
Этот шаблонный символ обычно используют для работы со словами, в которых постоянно встречаются опечатки, или для слов, допускающих разные варианты корректного написания:
$ echo "I like green color" | awk "/colou*r/{print $0}" $ echo "I like green colour " | awk "/colou*r/{print $0}"
Поиск слова, имеющего разные варианты написания
В этом примере одно и то же регулярное выражение реагирует и на слово «color», и на слово «colour». Это так благодаря тому, что символ «u», после которого стоит звёздочка, может либо отсутствовать, либо встречаться несколько раз подряд.
Ещё одна полезная возможность, вытекающая из особенностей символа звёздочки, заключается в комбинировании его с точкой. Такая комбинация позволяет регулярному выражению реагировать на любое количество любых символов:
$ awk "/this.*test/{print $0}" myfile

Шаблон, реагирующий на любое количество любых символов
В данном случае неважно сколько и каких символов находится между словами «this» и «test».
Звёздочку можно использовать и с классами символов:
$ echo "st" | awk "/s*t/{print $0}" $ echo "sat" | awk "/s*t/{print $0}" $ echo "set" | awk "/s*t/{print $0}"

Использование звёздочки с классами символов
Во всех трёх примерах регулярное выражение срабатывает, так как звёздочка после класса символов означает, что если будет найдено любое количество символов «a» или «e», а также если их найти не удастся, строка будет соответствовать заданному шаблону.
Регулярные выражения POSIX ERE
Шаблоны стандарта POSIX ERE, которые поддерживают некоторые утилиты Linux, могут содержать дополнительные символы. Как уже было сказано, awk поддерживает этот стандарт, а вот sed - нет.
Тут мы рассмотрим наиболее часто используемые в ERE-шаблонах символы, которые пригодятся вам при создании собственных регулярных выражений.
▍Вопросительный знак
Вопросительный знак указывает на то, что предшествующий символ может встретиться в тексте один раз или не встретиться вовсе. Этот символ - один из метасимволов повторений. Вот несколько примеров:
$ echo "tet" | awk "/tes?t/{print $0}" $ echo "test" | awk "/tes?t/{print $0}" $ echo "tesst" | awk "/tes?t/{print $0}"

Вопросительный знак в регулярных выражениях
Как видно, в третьем случае буква «s» встречается дважды, поэтому на слово «tesst» регулярное выражение не реагирует.
Вопросительный знак можно использовать и с классами символов:
$ echo "tst" | awk "/t?st/{print $0}" $ echo "test" | awk "/t?st/{print $0}" $ echo "tast" | awk "/t?st/{print $0}" $ echo "taest" | awk "/t?st/{print $0}" $ echo "teest" | awk "/t?st/{print $0}"

Вопросительный знак и классы символов
Если символов из класса в строке нет, или один из них встречается один раз, регулярное выражение срабатывает, однако стоит в слове появиться двум символам и система уже не находит в тексте соответствия шаблону.
▍Символ «плюс»
Символ «плюс» в шаблоне указывает на то, что регулярное выражение обнаружит искомое в том случае, если предшествующий символ встретится в тексте один или более раз. При этом на отсутствие символа такая конструкция реагировать не будет:
$ echo "test" | awk "/te+st/{print $0}" $ echo "teest" | awk "/te+st/{print $0}" $ echo "tst" | awk "/te+st/{print $0}"

Символ «плюс» в регулярных выражениях
В данном примере, если символа «e» в слове нет, движок регулярных выражений не найдёт в тексте соответствий шаблону. Символ «плюс» работает и с классами символов - этим он похож на звёздочку и вопросительный знак:
$ echo "tst" | awk "/t+st/{print $0}" $ echo "test" | awk "/t+st/{print $0}" $ echo "teast" | awk "/t+st/{print $0}" $ echo "teeast" | awk "/t+st/{print $0}"

Знак «плюс» и классы символов
В данном случае если в строке имеется любой символ из класса, текст будет сочтён соответствующим шаблону.
▍Фигурные скобки
Фигурные скобки, которыми можно пользоваться в ERE-шаблонах, похожи на символы, рассмотренные выше, но они позволяют точнее задавать необходимое число вхождений предшествующего им символа. Указывать ограничение можно в двух форматах:
- n - число, задающее точное число искомых вхождений
- n, m - два числа, которые трактуются так: «как минимум n раз, но не больше чем m».
Вот примеры первого варианта:
$ echo "tst" | awk "/te{1}st/{print $0}" $ echo "test" | awk "/te{1}st/{print $0}"
Фигурные скобки в шаблонах, поиск точного числа вхождений
В старых версиях awk нужно было использовать ключ командной строки --re-interval для того, чтобы программа распознавала интервалы в регулярных выражениях, но в новых версиях этого делать не нужно.
$ echo "tst" | awk "/te{1,2}st/{print $0}" $ echo "test" | awk "/te{1,2}st/{print $0}" $ echo "teest" | awk "/te{1,2}st/{print $0}" $ echo "teeest" | awk "/te{1,2}st/{print $0}"

Интервал, заданный в фигурных скобках
В данном примере символ «e» должен встретиться в строке 1 или 2 раза, тогда регулярное выражение отреагирует на текст.
Фигурные скобки можно применять и с классами символов. Тут действуют уже знакомые вам принципы:
$ echo "tst" | awk "/t{1,2}st/{print $0}" $ echo "test" | awk "/t{1,2}st/{print $0}" $ echo "teest" | awk "/t{1,2}st/{print $0}" $ echo "teeast" | awk "/t{1,2}st/{print $0}"

Фигурные скобки и классы символов
Шаблон отреагирует на текст в том случае, если в нём один или два раза встретится символ «a» или символ «e».
▍Символ логического «или»
Символ | - вертикальная черта, означает в регулярных выражениях логическое «или». Обрабатывая регулярное выражение, содержащее несколько фрагментов, разделённых таким знаком, движок сочтёт анализируемый текст подходящим в том случае, если он будет соответствовать любому из фрагментов. Вот пример:
$ echo "This is a test" | awk "/test|exam/{print $0}" $ echo "This is an exam" | awk "/test|exam/{print $0}" $ echo "This is something else" | awk "/test|exam/{print $0}"

Логическое «или» в регулярных выражениях
В данном примере регулярное выражение настроено на поиск в тексте слов «test» или «exam». Обратите внимание на то, что между фрагментами шаблона и разделяющим их символом | не должно быть пробелов.
Фрагменты регулярных выражений можно группировать, пользуясь круглыми скобками. Если сгруппировать некую последовательность символов, она будет восприниматься системой как обычный символ. То есть, например, к ней можно будет применить метасимволы повторений. Вот как это выглядит:
$ echo "Like" | awk "/Like(Geeks)?/{print $0}" $ echo "LikeGeeks" | awk "/Like(Geeks)?/{print $0}"

Группировка фрагментов регулярных выражений
В данных примерах слово «Geeks» заключено в круглые скобки, после этой конструкции идёт знак вопроса. Напомним, что вопросительный знак означает «0 или 1 повторение», в результате регулярное выражение отреагирует и на строку «Like», и на строку «LikeGeeks».
Практические примеры
После того, как мы разобрали основы регулярных выражений, пришло время сделать с их помощью что-нибудь полезное.
▍Подсчёт количества файлов
Напишем bash-скрипт, который подсчитывает файлы, находящиеся в директориях, которые записаны в переменную окружения PATH . Для того, чтобы это сделать, понадобится, для начала, сформировать список путей к директориям. Сделаем это с помощью sed, заменив двоеточия на пробелы:
$ echo $PATH | sed "s/:/ /g"
Команда замены поддерживает регулярные выражения в качестве шаблонов для поиска текста. В данном случае всё предельно просто, ищем мы символ двоеточия, но никто не мешает использовать здесь и что-нибудь другое - всё зависит от конкретной задачи.
Теперь надо пройтись по полученному списку в цикле и выполнить там необходимые для подсчёта количества файлов действия. Общая схема скрипта будет такой:
Mypath=$(echo $PATH | sed "s/:/ /g") for directory in $mypath do done
Теперь напишем полный текст скрипта, воспользовавшись командой ls для получения сведений о количестве файлов в каждой из директорий:
#!/bin/bash mypath=$(echo $PATH | sed "s/:/ /g") count=0 for directory in $mypath do check=$(ls $directory) for item in $check do count=$[ $count + 1 ] done echo "$directory - $count" count=0 done
При запуске скрипта может оказаться, что некоторых директорий из PATH не существует, однако, это не помешает ему посчитать файлы в существующих директориях.

Подсчёт файлов
Главная ценность этого примера заключается в том, что пользуясь тем же подходом, можно решать и куда более сложные задачи. Какие именно - зависит от ваших потребностей.
▍Проверка адресов электронной почты
Существуют веб-сайты с огромными коллекциями регулярных выражений, которые позволяют проверять адреса электронной почты, телефонные номера, и так далее. Однако, одно дело - взять готовое, и совсем другое - создать что-то самому. Поэтому напишем регулярное выражение для проверки адресов электронной почты. Начнём с анализа исходных данных. Вот, например, некий адрес:
Имя пользователя, username , может состоять из алфавитно-цифровых и некоторых других символов. А именно, это точка, тире, символ подчёркивания, знак «плюс». За именем пользователя следует знак @.
Вооружившись этими знаниями, начнём сборку регулярного выражения с его левой части, которая служит для проверки имени пользователя. Вот что у нас получилось:
^(+)@
Теперь - очередь имени хоста - hostname . Тут применимы те же правила, что и для имени пользователя, поэтому шаблон для него будет выглядеть так:
(+)
Имя домена верхнего уровня подчиняется особым правилам. Тут могут быть лишь алфавитные символы, которых должно быть не меньше двух (например, такие домены обычно содержат код страны), и не больше пяти. Всё это значит, что шаблон для проверки последней части адреса будет таким:
.({2,5})$
Прочесть его можно так: «Сначала должна быть точка, потом - от 2 до 5 алфавитных символов, а после этого строка заканчивается».
Подготовив шаблоны для отдельных частей регулярного выражения, соберём их вместе:
^(+)@(+).({2,5})$
Теперь осталось лишь протестировать то, что получилось:
$ echo "[email protected]" | awk "/^(+)@(+).({2,5})$/{print $0}" $ echo "[email protected]" | awk "/^(+)@(+).({2,5})$/{print $0}"

Проверка адреса электронной почты с помощью регулярных выражений
То, что переданный awk текст выводится на экран, означает, что система распознала в нём адрес электронной почты.
Итоги
Если регулярное выражение для проверки адресов электронной почты, которое встретилось вам в самом начале статьи, казалось тогда совершенно непонятным, надеемся, сейчас оно уже не выглядит бессмысленным набором символов. Если это действительно так - значит данный материал выполнил своё предназначение. На самом деле, регулярные выражения - это тема, которой можно заниматься всю жизнь, но даже то немногое, что мы разобрали, уже способно помочь вам в написании скриптов, которые довольно продвинуто обрабатывают тексты.
В этой серии материалов мы обычно показывали очень простые примеры bash-скриптов, которые состояли буквально из нескольких строк. В следующий раз рассмотрим кое-что более масштабное.
Уважаемые читатели! А вы пользуетесь регулярными выражениями при обработке текстов в сценариях командной строки?
Непрерывное выражение – это шаблон, который описывает набор строк. Регулярные выражения конструируются сходственно арифметическим выражениям с использованием различных операторов для комбинирования более маленьких выражений.
Непрерывные выражения (англ. regular expressions, сокр. RegExp, RegEx, жарг. регэкспы или регексы) - система синтаксического разбора текстовых фрагментов по формализованному шаблону, основанная на системе записи образцов для поиска. Образец (англ. pattern) задает правило поиска, по-русски также иногда кликается «шаблоном», «маской». Регулярные выражения произвели прорыв в электронной обработке контента в конце XX века. Они представляются развитием символов-джокеров (англ. wildcard characters).
Сейчас постоянные выражения используются многочисленными текстовыми редакторами и утилитами для поиска и изменения текста на базе выбранных правил. Почти многие языки программирования поддерживают регулярные выражения для работы со строчками. Например, Java, .NET Framework, Perl, PHP, JavaScript, Python и др. обладают встроенную поддержку постоянных выражений. Набор утилит (включая редактор sed и фильтр grep), считаемых в дистрибутивах UNIX, одним из первоначальных способствовал популяризации понятия регулярных выражений.
Одна из более полезных и многофункциональных команд в терминале Linux – бригада «grep». Grep – это акроним, какой расшифровывается как «global regular expression print» (то имеется, «искать везде соответствующие постоянному выражению строки и выводить их»).
Это значит, что grep возможно использовать для того, чтобы проглядеть, соответствуют ли вводимые данные заданным шаблонам. В простенькой форме grep используется для розыска совпадений буквенных шаблонов в текстовом файле. Это значивает, что если команда grep приобретает слово для поиска, она будет выводить каждую сохраняющую это слово строку файла.
Назначение grep - поиск строк согласно условию, изображенному регулярным выражением. Существуют изменения классического grep - egrep, fgrep, rgrep. Все они отточены под конкретные цели, при этом способности grep перекрывают весь функционал. Самым несложным примером использования команды представляется вывод строки, удовлетворяющей шаблону, из файла. Пример мы хотим найти строку, сохраняющую ‘user’ в файле /etc/mysql/my.cnf. Для этого воспользуемся последующей командой:
Grep user /etc/mysql/my.cnf
Grep сможет просто искать конкретное словечко:
Grep Hello ./example.cpp
Или строку, но в таком варианте её нужно заключать в кавычки:
Grep "Hello world" ./example.cpp
В добавление альтернативами программы являются egrep и fgrep, которые являются тем же самым, что и, соответственно, grep -E и grep -F. Варианты egrep и fgrep являются устаревшими, но работают для обратной совместимости. Вместо устаревших вариантов рекомендуется использовать grep -E и grep –F.
Команда grep сопоставляет строки исходных файлов с шаблоном, этим базовым регулярным выражением. Если файлы не указаны, используется стандартный ввод. Как как обычно каждая успешно сопоставленная строка копируется на стандартный вывод; если
исходных файлов чуть-чуть, перед найденной строкой выдается имя файла. В качестве шаблонов воспринимаются базовые непрерывные выражения (выражения, имеющие своими значениями цепочки символов, и использующие ограниченный комплекс алфавитно-цифровых и специальных символов).
Использование egrep в Linux
Egrep или grep -E - это другая версия grep или Extended grep. Эта версия grep превосходна и быстра, когда дело доходит до поиска шаблона регулярных выражений, поскольку она обрабатывает метасимволы как есть и не заменяет их как строки. Egrep использует ERE или Extended Extended Expression.
egrep - это урезанный вызов grep c ключом -E Отличие от grep заключается в возможности использовать расширенные непрерывные выражения с использованием символьных классов POSIX. Часто возникает задача поиска словечек или представлений, принадлежащих к одному типу, но с возможными вариациями в написании, такие как даты, фамилии файлов с некоторым расширением и стандартным названием, e-mail адреса. С другой стороны, имеется задачи по пребыванию вполне определенных слов, которые могут иметь различное начертание, либо розыск, исключающий отдельные символы или классы символов.
Для этих целей истины созданы некоторые системы, основанные на описании текста при помощи шаблонов. К таким системам причисляются и постоянные выражения. Два очень полезные спецсимвола — это ^ и $, которые обозначают начало и конец строки. Например, мы хотим получить всех пользователей, зарегистрированных в нашей системе, имя которых начинается на s. Тогда можно применить регулярное выражение «^s». Вы можете использовать бригаду egrep:
Egrep "^s" /etc/passwd
Есть возможность поиска по нескольким файлам и в подобном случае перед строкой выводится имя файла.
Egrep -i Hello ./example.cpp ./example2.cpp
А следующий запрос выводит весь код, исключая строки, содержащие только комментарии:
Egrep -v ^/ ./example.cpp
В виде egrep, даже если вы не избегаете метасимволы, команда будет относиться к ним как к специальным символам и заменять их своим особым значением вместо того, чтобы рассматривать их как часть строки.
Использование fgrep в Linux
Fgrep или Fixed grep или grep -F - это еще одна версия grep, какой-никакая необходима, когда дело доходит до поиска всей строки вместо регулярного понятия, поскольку оно не распознает ни регулярные выражения, ни метасимволы. Для поиска любой строки напрямую выбирайте эту версия grep.
Fgrep ищет полную строку и не распознает специальные символы как часть непрерывного выражения, несмотря на то экранированы символы или нет.
Fgrep -C 0 "(f|g)ile" check_file fgrep -C 0 "\(f\|g\)ile" check_file
Использование sed в Linux
sed (от англ. Stream EDitor) - потоковый текстовый редактор (а также язычок программирования), использующий различные предопределённые текстовые преобразования к последовательному потоку текстовых этих. Sed можно утилизировать как grep, выводя строки по шаблону базового регулярного выражения:
Sed -n /Hello/p ./example.cpp
Может быть использовать его для удаления строк (удаление всех пустых строк):
Sed /^$/d ./example.cpp
Основным инструментом работы с sed является выражение типа:
Sed s/искомое_выражение/чем_заменить/имя_файла
Так, образчик, если выполнить команду:
Sed s/int/long/ ./example.cpp
Выше рассмотрены различия меж «grep», «egrep» и «fgrep». Невзирая на различия в наборе используемых регулярных представлений и скорости выполнения, параметры командной строчки остаются одинаковыми для всех трех версий grep.
Регулярные выражения - это очень мощный инструмент для поиска текста по шаблону, обработки и изменения строк, который можно применять для решения множества задач. Вот основные из них:
- Проверка ввода текста;
- Поиск и замена текста в файле;
- Пакетное переименование файлов;
- Взаимодействие с сервисами, таким как Apache;
- Проверка строки на соответствие шаблону.
Это далеко не полный список, регулярные выражения позволяют делать намного больше. Но для новых пользователей они могут показаться слишком сложными, поскольку для их формирования используется специальный язык. Но учитывая предоставляемые возможности, регулярные выражения Linux должен знать и уметь использовать каждый системный администратор.
В этой статье мы рассмотрим регулярные выражения bash для начинающих, чтобы вы смогли разобраться со всеми возможностями этого инструмента.
В регулярных выражениях могут использоваться два типа символов:
- обычные буквы;
- метасимволы.
Обычные символы - это буквы, цифры и знаки препинания, из которых состоят любые строки. Все тексты состоят из букв и вы можете использовать их в регулярных выражениях для поиска нужной позиции в тексте.
Метасимволы - это кое-что другое, именно они дают силу регулярным выражениям. С помощью метасимволов вы можете сделать намного больше чем поиск одного символа. Вы можете искать комбинации символов, использовать динамическое их количество и выбирать диапазоны. Все спецсимволы можно разделить на два типа, это символы замены, которые заменяют собой обычные символы, или операторы, которые указывают сколько раз может повторяться символ. Синтаксис регулярного выражения будет выглядеть таким образом:
обычный_символ спецсимвол_оператор
спецсимвол_замены спецсимвол_оператор
- \ - с обратной косой черты начинаются буквенные спецсимволы, а также он используется если нужно использовать спецсимвол в виде какого-либо знака препинания;
- ^ - указывает на начало строки;
- $ - указывает на конец строки;
- * - указывает, что предыдущий символ может повторяться 0 или больше раз;
- + - указывает, что предыдущий символ должен повторится больше один или больше раз;
- ? - предыдущий символ может встречаться ноль или один раз;
- {n} - указывает сколько раз (n) нужно повторить предыдущий символ;
- {N,n} - предыдущий символ может повторяться от N до n раз;
- . - любой символ кроме перевода строки;
- - любой символ, указанный в скобках;
- х|у - символ x или символ y;
- [^az] - любой символ, кроме тех, что указаны в скобках;
- - любой символ из указанного диапазона;
- [^a-z] - любой символ, которого нет в диапазоне;
- \b - обозначает границу слова с пробелом;
- \B - обозначает что символ должен быть внутри слова, например, ux совпадет с uxb или tuxedo, но не совпадет с Linux;
- \d - означает, что символ - цифра;
- \D - нецифровой символ;
- \n - символ перевода строки;
- \s - один из символов пробела, пробел, табуляция и так далее;
- \S - любой символ кроме пробела;
- \t - символ табуляции;
- \v - символ вертикальной табуляции;
- \w - любой буквенный символ, включая подчеркивание;
- \W - любой буквенный символ, кроме подчеркивания;
- \uXXX - символ Unicdoe.
Важно отметить, что перед буквенными спецсимволами нужно использовать косую черту, чтобы указать, что дальше идет спецсимвол. Правильно и обратное, если вы хотите использовать спецсимвол, который применяется без косой черты в качестве обычного символа, то вам придется добавить косую черту.
Например, вы хотите найти в тексте строку 1+ 2=3. Если вы используете эту строку в качестве регулярного выражения, то ничего не найдете, потому что система интерпретирует плюс как спецсимвол, который сообщает, что предыдущая единица должна повториться один или больше раз. Поэтому его нужно экранировать: 1 \+ 2 = 3. Без экранирования наше регулярное выражение соответствовало бы только строке 11=3 или 111=3 и так далее. Перед равно черту ставить не нужно, потому что это не спецсимвол.
Примеры использования регулярных выражений
Теперь, когда мы рассмотрели основы и вы знаете как все работает, осталось закрепить полученные знания про регулярные выражения linux grep на практике. Два очень полезные спецсимвола - это ^ и $, которые обозначают начало и конец строки. Например, мы хотим получить всех пользователей, зарегистрированных в нашей системе, имя которых начинается на s. Тогда можно применить регулярное выражение "^s" . Вы можете использовать команду egrep:
egrep "^s" /etc/passwd
Если мы хотим отбирать строки по последнему символу в строке, что для этого можно использовать $. Например, выберем всех системных пользователей, без оболочки, записи о таких пользователях заканчиваются на false:
egrep "false$" /etc/passwd

Чтобы вывести имена пользователей, которые начинаются на s или d используйте такое выражение:
egrep "^" /etc/passwd
 Такой же результат можно получить, использовав символ "|". Первый вариант более пригоден для диапазонов, а второй чаще применяется для обычных или/или:
Такой же результат можно получить, использовав символ "|". Первый вариант более пригоден для диапазонов, а второй чаще применяется для обычных или/или:
egrep "^" /etc/passwd

Теперь давайте выберем всех пользователей, длина имени которых составляет не три символа. Имя пользователя завершается двоеточием. Мы можем сказать, что оно может содержать любой буквенный символ, который должен быть повторен три раза, перед двоеточием:
egrep "^\w{3}:" /etc/passwd

Выводы
В этой статье мы рассмотрели регулярные выражения Linux, но это были только самые основы. Если копнуть чуть глубже, вы найдете что с помощью этого инструмента можно делать намного больше интересных вещей. Время, потраченное на освоение регулярных выражений, однозначно будет стоить того.
На завершение лекция от Яндекса про регулярные выражения:
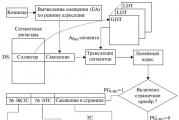
Регулярные выражения Bash командной оболочки предназначены для одного из основных инструментов, позволяющих взаимодействовать между пользователем и операционной системой. Через оболочку пользователь может управлять файлами и каталогами, присутствующими в файловой системе машины, обрабатывать их содержимое и выполнять другие программы, используя клавиатуру своего терминала в качестве блока ввода и буквенно-цифровой экран терминала в качестве выходного устройства.
Регулярные выражения Bash разработаны Брайаном Фоксом для проекта GNU как альтернативная смена ПО для оболочки Bourne. Командный язык был издан в 1989 году и массово распространился в качестве оболочки входа по умолчанию для дистрибутивов Linux и MacOS через Apple (прежде OS X). Версия тоже доступна для Windows 10 и является оболочкой пользователя по умолчанию в Solaris 11.
Bash - это инструктивный процессор, традиционно работающий в текстовом терминале, где разработчик запускает команды, вызывающие действия. Регулярные выражения Bash читаются и исполняются из файла, именуемого сценарием оболочки. Вместе с Unix он распознает имена файлов (сравнение подстановочных символов), протоколы, документы, подстановку директив и структуры управления для тестирования критериев. В главных словах синтаксис и другие ключевые индивидуальности языка воспроизводятся из csh и ksh. Bash - это POSIX- совместимая оболочка, но с некоторыми расширениями. Название оболочки - это сокращение от
Брайан Фокс начал кодировать "Баша" 10 января 1988 года после того, как Ричард Столлман был недоволен отсутствием прогресса в разработках бесплатной оболочки, которая могла бы запускать существующие сценарии. Фокс выпустил Bash как бета-версию 8 июня 1989 года и оставался основным разработчиком проекта с середины 1992 года и до середины 1994 года, после чего он был уволен из ФСФ, а его место занял Чет Рами.
В этот период Bash была самой популярной программой среди пользователей Linux, став интерактивной оболочкой по умолчанию в различных дистрибутивах этой операционной системы, а также в MacOS от Apple. Bash также была вкраплена в Microsoft Win с Cygwin, в DOS по DJGPP проекту и Android с помощью различных приложений эмуляции терминала.
В начале сентября 2014 года была обнаружена приличная брешь безопасности в "Баше" версии 1.03, вышедшей в августе 1989 года, получившая название Shellshock, которая привела к целому ряду атак через Интернет. Ошибка считалась серьезной, поскольку с использованием Bash стали уязвимыми, что позволило выполнять произвольный код. Патчи для исправления ошибок стали доступными сразу же после их обнаружения, но не все компьютеры были обновлены.
Особенности синтаксиса оболочки
Bash является надмножеством команд оболочки Bourne и использует расширение брекетов, завершение командной строки, базовую отладку и обработку исключений с применением ловушки среди других функций. Выполняет подавляющее большинство сценариев оболочки Bourne без изменений, за исключением сценариев, которые по-разному интерпретируются или пытаются запустить системную команду. Регулярные выражения Bash grep, а также инструменты GNU используют сжатый способ сканирования ошибок ПО и устанавливают статус выхода, что позволяет потокам переходить к традиционным пунктам назначения.
Если разработчик жмет кнопку табуляции в командной оболочке, Bash автоматически применяет окончание командной строки, для того чтобы подходить к типизированным именам программ, файлов и переменных. Система прекращения командной строки бесконечно гибкая и управляемая, и ее нередко составляют с функциями, хранящими аргументы и имена файлов для конкретных программ и заданий. Синтаксис Bash владеет достаточным количеством расширений, недостающих в оболочке Bourne.
Регулярные выражения Bash: исполнение цельночисленных расчетов арифметической оценки, употребляется ((...)) команда и $ ((...)) аргумент синтаксиса, упрощающий переадресовывание ввода-вывода. Например, он имеет возможность перенаправлять вывод (stdout) и сбой (stderr) синхронно с поддержкой &>оператора. Настоящее легче ввести, нежели эквивалент оболочки Bourne " command > file 2>&1".
Bash использует замещение процесса с поддержкой синтаксиса регулярных выражений "Линукс" и подменяет вывод команды (ввода), традиционно применяющий имя файла. При использовании ключевого слова «функция», объявления Bash несовместимы со сценариями Bourne и Korn, так как оболочка Korn имеет ту же проблему при применении «функции», но она принимает тот же синтаксис объявления функции, что и вышеназванные оболочки, являясь POSIX-совместимой.
Из-за этих и других отличий сценарии редко выполняются под интерпретаторами Bourne и Korn, если они не были специально написаны с учетом этой совместимости, что нужно учитывать при планировании работы с регулярными выражениями Bash. Ассоциативные массивы позволяют поддельную поддержку индексированных массивов, аналогично AWK. Bash 4.x не был интегрирован в новую версию MacOS из-за ограничений лицензии. Пример ассоциативного массива.

Оболочка имеет два режима исполнения команд: пакетный и параллельный. Команды в пакетном режиме разделены символом «;». Регулярные выражения Bash, пример:
- command1;
- command2.
В этом примере, когда команда 1 завершена, выполняется команда 2. И так же можно выполнить фоновое выполнение команды 1 с помощью (symbol &) в конце выполнения, процесс будет выполняться в фоновом режиме, возвращая сразу управление оболочке и позволяя пользователю применять исполняемые команды.

Для одновременного выполнения команд 1 и 2 они должны быть выполнены в оболочке следующим образом:
- command1 & command2.
В этом случае команда 1 выполняется в фоновом режиме & symbol, возвращая сразу управление оболочке, которая выполняет команду 2 на переднем плане. Регулярные выражения Bash grep можно остановить и вернуть управление, набрав Ctrl + z, пока процесс выполняется на переднем плане. Список всех процессов, как в фоновом режиме, так и в режиме остановки, может быть, достигнут путем запуска jobs.
Состояние процесса можно изменить с помощью различных команд. Команда "fg" выводит процесс на передний план, а "bg"-набор останавливает процесс, выполняющийся в фоновом режиме. Bg" и "fg" могут принять идентификатор работы в качестве своего первого аргумента, чтобы указать, в каком процессе действовать. Без этого они используют процесс по умолчанию, обозначенный знаком «плюс» в выводе "jobs". Команда "kill" может использоваться для завершения процесса преждевременно, отправив ему сигнал. Идентификатор задания должен быть указан после знака процента:
- kill -s SIGKILL% 1 или kill -9%.
Bash поставляет «условное исполнение» разделителям команд, которые выполняют команды "contingent" по коду выхода, установленного командой прецедента. Внешняя команда, называемая "bashbug", сообщает об ошибках оболочки. Когда команда вызывается, она запускает редактор по умолчанию для пользователя с заполненной формой. Форма отправляется сторонам Bash или, возможно, другим адресам электронной почты, обеспечив глобально замену регулярных выражений Bash.

Когда Bash начинает функционировать, он исполняет различные точечные файлы. Даже по сходным командам сценариев, имеющих разрешение на исполнение и распоряжение интерпретатора, к примеру:
- #!/bin/bash.

Файлы инициализации, применяемые Bash выражения с присвоением не требуют этого. Порядок исполнения файлов:
- При запуске оболочки он читает и исполняет /etc/profile, в случае если он имеется.
- Данный файл инициирует /etc/bash.bashrc.
- После определения данного файла он отыскивает ~/.bash_profile, считывая и исполняя 1-й, существующий и читаемый.
- Если оболочка следует из , он определяет и исполняет ~/.bash_logout.
- Во время запуска в роли оболочки он определяет и исполняет /etc/bash.bashrc, а потом ~/.bashrc.
- Настоящее имеет возможность запрещения через "--norc" опцию.
- Параметр "--rcfile" file вынуждает Bash прочитывать и исполнять его.
- Сопоставление с Bourne shell и csh startup , выходят из оболочки "Борна" и csh. Они разрешают сузить общее использование файлов с Bourne и позволить отдельные функции пуска, известные юзерам csh.

Вызов Bash с -posix опцией или указание set -o posix в скрипте заставляет регулярное выражение для экранирования Bash очень точно соответствовать стандарту POSIX 1003.2. Сценарии оболочки, предназначенные для переносимости, должны по крайней мере учитывать оболочку Bourne, которую она намеревается заменить. У Bash есть определенные функции, которых не хватает традиционной оболочке Bourne. К ним относятся:
- Некоторые расширенные варианты вызова.
- Подстановка команд с использованием нотации $ (). Эта функция является частью стандарта POSIX 1003.2.
- Расширение скобок.
- Некоторые операции с массивами и ассоциативные массивы.
- Расширение тестовой конструкции с двойными скобками.
- Арифметико-оценочная конструкция регулярных выражений Bash в "if".
- Некоторые операции манипуляции строкой.
- Замена процесса.
- Оператор соответствия регулярному выражению.
- "Баш"-специфические встроенные Coprocesses.
Арифметические выражения Bash используют "readline" для предоставления быстрых клавиш и редактирования командной строки с использованием привязок клавиш по умолчанию (Emacs). Vi-привязки могут быть включены при запуске "set -o vi".

Подстановка скобок, называемая также чередованием, - это функция, что копируется из оболочки "C". Она генерирует набор альтернативных комбинаций. Сгенерированные результаты не обязательно должны существовать в виде файлов. Результаты каждой расширенной строки не сортируются и сохраняются в порядке справа. Пользователи не должны использовать расширения скобок в переносных сценариях оболочки, потому что оболочка Bourne не производит одинаковый вывод.
Когда расширение скобки сочетается с подстановочными знаками, скобки сначала расширяются, а затем получаемые подстановочные знаки заменяются. В дополнение к чередованию расширение брекета может использоваться для последовательных диапазонов между двумя целыми числами или символами, разделенными двойными точками. Более новые версии использования регулярных выражений Bash позволяют третьему целому числу указать приращение.
Когда расширение брекета сочетается с переменным расширением, оно выполняется после расширения брекета, которое в некоторых случаях может потребовать использования "eval" встроенного, таким образом:
- $ start = 1 ;
- end = 10 $ echo { $ start .. $ end } # не может расширяться из-за порядка оценки {1..10};
- $ eval echo { $ start .. $ end } # расширение переменной происходит, тогда результирующая строка оценивается: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10.
Синтаксические аспекты языка "Баша"

Сценарии оболочки должны храниться в текстовом файле ASCII, созданном с использованием программы «editor», которая не вводит дополнительные символы или последовательности для форматирования текста. Например, редакторы, подходящие для создания сценариев оболочки, - это программы vi или Emacs, доступные в UNIX / Linux, или такие программы, как «Блокнот», TextEdit и UltraEdit в Microsoft Windows.
Хорошей практикой является вставка в первую строку каждого сценария Bash регулярки, последовательности «#! / Bin / bash», которая показывает абсолютный путь программы в файловой системе машины, на которой нужно запустить скрипт. Таким образом, можно запустить его непосредственно в командной строке, не указывая имя файла в качестве аргумента команды «bash».
Указание программы-переводчика, которая будет использоваться операционной системой для перевода и выполнения инструкций скрипта, предоставляется в первой строке самого скрипта, сразу после последовательности символов «#!». Считается, что исполняемый файл интерпретатора находится в каталоге « / bin», но в разных системах он может быть установлен в других каталогах, например:
- « / usr / bin », « / usr / local / bin ».
В общем случае символ «#» позволяет вводить комментарий в источнике сценария. Любой символ в строке сценария после символа «#» игнорируется командным интерпретатором. Фактически он часто используется для вставки комментариев в источник сценария для описания его работы или для объяснения влияния конкретных команд. Как и при вставке команд в интерактивном режиме, даже при кодировании скрипта, каждая инструкция программы может быть записана на отдельной строке или разбита на несколько строк и заканчивает каждую строку, кроме последней, символом « \ ». Дополнительные инструкции можно сообщать в той же строке, используя «;».
Инструкции программы могут быть «отступом», чтобы сделать исходный код более удобочитаемым, но следует обратить внимание на использование пробелов. Интерпретатор Bash более «разборчив», чем другие интерпретаторы или компиляторы, и в некоторых случаях не допускается вставка произвольных пространств между членами, составляющими инструкции, в других случаях использование пространства имеет важное значение для правильной интерпретации инструкции.
Нет никаких символов для разграничения блоков инструкций, вставленных в структуру управления, например, которые должны повторяться в структуре итеративного управления. С другой стороны, существуют соответствующие языковые ключевые слова, которые позволяют правильно идентифицировать начало и конец блока. Эти ключевые слова различаются в зависимости от инструкции, используемой для управления потоком программы. В синтаксисе примеров "match" регулярных выражений Bash некоторые символы принимают особое значение, то есть если они присутствуют в строке символов или в качестве аргумента команды, то выполняют очень точную функцию.

С минимальным упрощением можно сказать, что оболочка - это программа, которая интерактивно всегда выполняет одну и ту же операцию. Она ожидает ввода команды в качестве входных данных, оценивает ее, чтобы убедиться, что команда синтаксически корректна, и выполняет ее, затем возвращается, чтобы ждать следующей команды. Этот процесс заканчивается, когда оболочка получает сигнал, указывающий, что вход завершен и никакие другие команды не будут отправлены на него. В этот момент завершается программа оболочки, освобождая выделенную память и другие машинные ресурсы, доступные операционной системе.
Сценарий запускается автоматически операционной системой, когда пользователь входит в саму систему, то есть может быть выполнен пользователем посредством команды, заданной на уже открытой оболочке, или с помощью специальных графических утилит, если он работает с системой с графическим интерфейсом пользователя. Например, на компьютере Apple Macintosh под управлением Mac OS X можно использовать командную оболочку, запустив утилиту Terminal, расположенную в Utility в папке «Приложение».
На рабочей станции Linux с графическим менеджером рабочего стола, например GNOME или KDE, можно открыть командную оболочку, выбрав программу «Терминал» из меню «Приложения → Аксессуары». После активации командной оболочки можно просмотреть имя используемой нами оболочки, выполнив следующие команды:
- $ echo;
- $SHELL /bin/bash.
Если оболочка по умолчанию не является Bash, можно проверить, присутствует ли она в системе в одном из каталогов, перечисленных в переменной среды PATH, используя команду «which», и выполнить ее с помощью команды «bash»:
- $ echo $SHELL /bin/tcsh $ which bash /bin/bash $ bash bash-2.03$.
Оболочка, таким образом, работает в интерактивном режиме, получая входные данные в каждую отдельную команду и параметры, указанные в командной строке, и выполняя саму команду. Вывод отображается в том же окне терминала. Каждая команда, передаваемая оболочке, заканчивается нажатием клавиши Invio/Enter. Можно выпустить несколько команд в одной строке, отделяя их друг от друга символом «;». Также возможно разбить вставку команды на две или более строк, заканчивая каждую промежуточную строку символом « \ ».

Обычно на языках программирования кавычки и двойные кавычки используются для разграничения строк, а использование одного или другого символа зависит от синтаксиса, принятого на определенном языке. В языках сценариев использование кавычек и обратных ссылок имеет другое значение, и Bash в этом не является исключением.
Одиночные кавычки используются для разграничения строк символов. Интерпретатор не входит в содержимое строки и просто использует последовательность символов, разделенных кавычками. Таким образом, символы, которые иначе принимают другое значение, также могут быть частью строки. Единственный символ, который не может использоваться в строке, ограниченной кавычками, - это те же самые кавычки. Для определения такой строки необходимо разграничить ее кавычками.
Для разграничения строк используются двойные кавычки, однако если строка ограничена этим символом, интерпретатор выполняет так называемую «интерполяцию» и разрешает значение любых переменных в регулярных выражениях Bash в строке. На практике если в строке, заключенной в двойные кавычки, есть ссылка на переменную, то в строке имя переменной заменяется ее значением. Чтобы напечатать символы, например двойные кавычки или доллар, которые иначе интерпретировались бы и принимали бы другое значение, необходимо прописывать префикс каждого из них символом « \ » обратной косой черты. Чтобы напечатать символ обратной косой черты в строке, ограниченной двойными кавычками, нужно вернуть две обратные косые черты.
Характер обратного хода имеет наиболее характерное поведение, типичное для языков сценариев, и отсутствует на основных языках программирования высокого уровня. Кавычка позволяет разграничить строку, которая интерпретируется Bash как команда и должна быть выполнена, возвращаясь в качестве значения выходных данных на тот же продукт канала выходного стандарта.

Если нужно выполнить оболочку таким образом, чтобы она обрабатывала последовательность команд, показанных в текстовом файле ASCII:
- $ pwd ;
- echo $SHELL ;
- hostaname /home/marco /bin/bash aquilante $ echo \ > $SHELL /bin/bash.
Если нужно подготовить файл под названием «script.sh », который хранится в домашнем каталоге, содержимое файла может быть следующим:
- echo -n "Oggi e" il " 2 date +%d/%m/%Y.
Запускают этот очень простой скрипт, указав имя файла в командной строке, с которой вызывается оболочка:
- $ bash script.sh Oggi e" il 10/6/2011.
Оболочка также может принимать последовательность команд для выполнения через канал, который перенаправляет вывод другой команды на стандартный вход Bash:
- $ cat script.sh | bash Oggi e" il 10/6/2011.
Можно выделить строку регулярных выражений Bash-программы с обозначением «#!». Абсолютный путь интерпретатора, который будет использоваться для выполнения скрипта, запускают напрямую без ОС, запустив Bash и передав скрипт во вход:
- $ cat script.sh #!/bin/bash echo -n "Oggi e" il " date +%d/%m/%Y $ chmod 755 script.sh $ ls -l script.sh -rwxr-xr-x 1 marco users 49 18 Apr 23:58 script.sh $ ./script.sh Oggi e" il 10/6/2011.
В последней команде предыдущего примера, непосредственно вызывающей выполнение скрипта, хранящегося в файле «script.sh», присутствующем в текущем каталоге, указан относительный путь « ./ » до имени файла. Необходимо указать путь к каталогу, в котором находится исполняемый скрипт, потому что часто по соображениям безопасности текущий каталог отсутствует в списке каталогов, в которых оболочка должна искать внешние исполняемые команды. Список таких каталогов хранится в переменных регулярных выражениях Bash.
Преимущества операционной системы с Bash
Это самый эффективный язык сценариев оболочки. Он дает пользователю простой способ автоматизировать работу, если он уже знаком с применением оболочки в интерактивном режиме. Если разработчик программирует системы, тогда он должен знать, как работает оболочка.
Если сравнить скрипты с изучением конфигурации или системы автоматизации "yaml" или "json", они намного более универсальны. Сценарии Bash более просты, потому что скрипт работает по умолчанию.
Bash - более простой язык, и это заставляет разработчиков сосредоточиться на других сложностях системы. Бэш прекрасно работает для написания оболочки. Все остальное в основном либо использует оболочку для команд, либо реализует свою собственную оболочку, копируя хорошие части из нее. Кроме того, существуют хорошие конструкторы регулярных выражений Bash, которые значительно упрощают работу с оболочкой.
С помощью Bash разработчики могут использовать интерактивный веб-опыт, применяя опыт командной строки Linux без границ времени и места. Для использования этой возможности не требуются строгие правила и усилия, и пользователи могут получить доступ к аутентифицированной рабочей станции, управляя ресурсами и средой Azure одним кликом, даже когда они используют мобильные приложения Azure, Azure Portal и Azure Documentation.
В отличие от традиционной среды командной строки, нет необходимости устанавливать и выбирать инструменты перед началом работы и можно сэкономить время и усилия с помощью Bash. Все инструменты CLI, такие как текстовые, сборки, контейнеры и исходные доступны в Bash, и можно использовать безопасную и простую аутентификацию инструментов с помощью CLI 2.0.
Мы рассмотрели примеры регулярных выражений Bash. Удачи в освоении!