Физические ограничения вычислений. Поиск альтернативы транзисторам
Каждый атом Вселенной, а не только различные макроскопические объекты, способен хранить информацию. Акты взаимодействия атомов можно описать как элементарные логические операции, в которых меняют свои значения квантовые биты – элементарные единицы квантовой информации. Парадоксальный, но многообещающий подход Сета Ллойда позволяет элегантно решить вопрос о постоянном усложнении Вселенной: ведь даже случайная и очень короткая программа в ходе своего исполнения на компьютере может дать крайне интересные результаты. Вселенная постоянно обрабатывает информацию – будучи квантовым компьютером огромного размера, она все время вычисляет собственное будущее. И даже такие фундаментальные события, как рождение жизни, половое размножение, появление разума, можно и должно рассматривать как последовательные революции в обработке информации.
Теорема Марголюса – Левитина гласит, что максимальная частота, с которой физическая система (электрон, например) может переходить из одного состояния в другое, пропорциональна энергии системы; чем больше доступной энергии, тем меньше времени нужно электрону, чтобы перейди отсюда туда. Эта теорема очень общая. Для нее несущественно, какая система хранит и обрабатывает информацию; важно только, сколько энергии есть в системе, чтобы обрабатывать эту информацию. Рассмотрим, например, атомы и электроны в моем компьютере. Их температура немного выше комнатной. Каждый атом и электрон раскачиваются, и количество энергии, связанной с типичными колебаниями, остается одним и тем же для атома и для электрона. Энергия на одно колебание просто пропорциональна температуре, независимо от того, говорим мы об атоме или об электроне. Следовательно, частота, с которой электрон в компьютере может перемещаться от одного состояния к другому, отсюда туда, или от 0 к 1, – такая же, что и скорость, с которой атом может переходить из одного состояния в другое. Электроны и атомы инвертируют свои биты с одной и той же частотой.
Теорема Марголюса – Левитина дает метод для вычисления максимальной частоты, с которой бит может менять свое состояние. Возьмем количество энергии, доступной для инвертирования бита, умножим ее на 4 и разделим на постоянную Планка. В результате мы получим число возможных инверсий бита за секунду. Применяя эту формулу к атомам и электронам в моем компьютере, мы выясним, что каждый колеблющийся атом и электрон изменяют свое состояние и свой бит примерно 30 трлн (30 х 1012) раз в секунду.
Скорость, с которой атомы и электроны инвертируют свои биты, обычно намного больше, чем скорость, с которой это делает обычный компьютер. Компьютер, на котором я печатаю текст, вкладывает в зарядку и разрядку конденсаторов, которые хранят его биты, в миллиард раз больше энергии, чем используют атомы и электроны на свои колебания и на инверсию своих битов. Но мой компьютер действует в 10 000 раз медленнее атомов. Медлительность моего компьютера не противоречит теореме Марголюса – Левитина. Эта теорема дает только верхний предел того, как быстро может менять свое состояние бит. Бит может делать это медленнее максимальной скорости, допускаемой теоремой. Квантовый компьютер, однако, всегда инвертирует свои биты с максимальной скоростью.
Теорема Марголюса – Левитина устанавливает предел количества элементарных операций (опов), которые может выполнять бит в секунду. Предположим, что мы оставим неизменным количество энергии, доступное для изменения состояния битов, но теперь разделим эту энергию между двумя битами. Каждый из этих двух битов получит половину энергии нашего первоначального бита и сможет работать вдвое медленнее. Но общее количество переходов в секунду останется тем же.
Если разделить количество доступной энергии между десятью битами, то каждый из них будет менять свое состояние в десять раз медленнее, но общее количество переходов в секунду останется тем же. Так же как она безразлична к размерам системы, эта теорема не «заботится» о том, откуда берется доступная энергия. Максимальное количество операций в секунду – это энергия E , умноженная на 4 и деленная на постоянную Планка.
Теорема Марголюса – Левитина позволяет легко вычислить мощность абсолютного ноутбука. Энергию абсолютного ноутбука, доступную для вычисления, можно вычислить с помощью известной формулы Эйнштейна E = mc? , где E – энергия, m – масса ноутбука, а c – скорость света. Введя в эту формулу массу нашего абсолютного компьютера (один килограмм) и скорость света (300 млн м в секунду), мы обнаружим, что у абсолютного ноутбука есть почти 100 миллионов миллиардов (1017) джоулей доступной энергии для выполнения вычислений. Если привести тот же результат в более знакомой форме энергии, у ноутбука есть около 20 млрд (2 х 1013) килокалорий доступной энергии, что эквивалентно 100 млрд шоколадных батончиков. Это очень много энергии.
Другой знакомый нам эквивалент – это количество энергии, высвобождаемой при ядерном взрыве. У абсолютного ноутбука есть двадцать мегатонн (20 млн т в тротиловом эквиваленте) энергии, доступной для вычисления. Это сопоставимо с количеством энергии, высвобождаемой при взрыве большой водородной бомбы. По существу, когда наш абсолютный ноутбук выполняет вычисления на максимальной скорости, используя для изменения состояния битов каждую доступную калорию, изнутри это выглядит как ядерный взрыв. Элементарные частицы, которые хранят и обрабатывают информацию в абсолютном ноутбуке, движутся при температуре в миллиард градусов. Абсолютный ноутбук похож на маленький кусочек Большого взрыва. (Технологии упаковки должны будут совершить серьезный прорыв, прежде чем кто-то захочет положить абсолютный ноутбук к себе на колени.) В итоге количество операций, которое может выполнить наш маленький, но мощный компьютер, составляет огромную величину: миллион миллиардов миллиардов миллиардов миллиардов миллиардов (1051) операций в секунду. Компании Intel есть, к чему стремиться.
Но сколь велик путь, который придется пойти компании Intel? Вспомним закон Мура: в последние полвека количество информации, которую могут обрабатывать компьютеры, и скорость, с которой они ее обрабатывают, удваивается каждые восемнадцать месяцев. Множество технологий – последней из них стали интегральные схемы – сделали возможным такой рост мощности обработки информации. Нет никаких причин, по которым закон Мура должен продолжать действовать год за годом; это закон человеческой изобретательности, а не закон природы. В какой-то момент закон Мура перестанет работать. В частности, никакой ноутбук не может вести вычисления быстрее, чем абсолютный ноутбук, описанный выше.
Но сколько времени потребуется компьютерной индустрии, чтобы при существующей скорости технического прогресса создать абсолютный ноутбук? Мощность компьютеров удваивается каждые полтора года. За пятнадцать лет она удваивается десять раз, то есть увеличивается на три порядка. Иначе говоря, нынешние компьютеры в миллиард раз быстрее, чем были гигантские электромеханические машины всего пятьдесят лет назад. Нынешние компьютеры выполняют порядка триллиона логических операций в секунду (1012). Следовательно (если закон Мура продержится до тех пор), мы сможем купить абсолютный ноутбук в магазине примерно в 2205 г.
Количество энергии, доступной для вычислений, ограничивает скорость вычислений. Но скорость вычислений – не единственная характеристика, которая нас интересует, когда мы покупаем новый ноутбук. Не менее важен объем памяти. Какова емкость абсолютного жесткого диска?
Внутренности абсолютного ноутбука заполнены элементарными частицами, которые раскачиваются, как сумасшедшие, при миллиарде градусов. Те же методы, которые специалисты по космологии используют для измерения количества информации, присутствовавшего во время Большого взрыва, можно использовать для измерения числа битов, запечатленных абсолютным ноутбуком. Раскачивающиеся частицы абсолютного ноутбука запечатлевают около 10 000 миллиардов миллиардов миллиардов битов (1031). Это очень много битов – намного больше, чем информации, которая хранится на жестких дисках всех компьютеров в мире.
Сколько времени потребуется компьютерной индустрии, чтобы реализовать технические требования к памяти абсолютного ноутбука? Закон Мура для объема памяти сейчас действует быстрее, чем закон Мура для скорости вычислений: емкость жесткого диска удваивается почти каждый год. При таком темпе для того, чтобы создать абсолютный жесткий диск, потребуется всего семьдесят пять лет.
Конечно, закон Мура может действовать лишь до тех пор, пока человеческая изобретательность будет находить новые способы уменьшать размеры компьютеров. Трудно постоянно уменьшать размеры соединений, транзисторов и конденсаторов, и чем более миниатюрными становятся компоненты компьютеров, тем труднее ими управлять. Закон Мура уже много раз объявляли мертвым из-за той или иной хитроумной технической проблемы, которая на первый взгляд казалась неразрешимой. Но каждый раз хитроумные инженеры и ученые находили новый способ разрубить узел технологий. Кроме того, как мы уже сказали, у нас есть надежные экспериментальные данные о том, что компоненты компьютеров можно уменьшить до размера атомов. Существующие квантовые компьютеры уже хранят и обрабатывают информацию на уровне атомов. При нынешней скорости миниатюризации закон Мура не позволит достичь уровня атомов еще в течение сорока лет, так что определенные надежды в его отношении сохраняются.
Многие энтузиасты компьютерных технологий со стажем помнят времена, когда частоты процессоров измерялись в мегагерцах, и производители (то есть Intel и AMD) старались опередить друг друга по этому показателю. Затем уровень энергопотребления и теплоотдача процессоров выросли настолько, что продолжать эту гонку стало невозможным. В последние годы начали наращивать количество процессорных ядер, но в результате был достигнут предел, когда этот рост стал невыгоден. Теперь получение наибольшей мощности на Ватт стало главным фактором производительности.
Все эти изменения произошли не потому, что разработчики столкнулись с физическими пределами дальнейшего развития существующих процессоров. Скорее, производительность оказалась ограничена тем фактом, что прогресс в некоторых областях — в первую очередь энергоэффективности — был медленнее прогресса в других сферах, вроде расширения функциональных возможностей и наборов команд. Однако может ли быть так, что теперь физический предел процессоров и их вычислительной мощности уже близок? Игорь Марков из Университета Мичигана рассмотрел этот вопрос в статье в журнале Nature.
Рассматриваем преграды
Марков отмечает, что, основываясь на чисто физических ограничениях, некоторые учёные подсчитали, что закона Мура хватит ещё на сотни лет. С другой стороны, группа International Technology Roadmap for Semiconductors (ITRS) даёт ему пару десятилетий жизни. Впрочем, прогнозы ITRS можно ставить под сомнение: раньше эта группа предсказывала процессоры с частотой 10 ГГц во времена чипов Core2. Причина этого расхождения состоит в том, что многие жёсткие физические ограничения так и не вступили в игру.
Например, крайний предел размера функционального блока — один атом, что представляет собой конечный физический предел. Но задолго до того, как получится достичь этого предела, физика ограничивает возможность точно контролировать поток электронов. Другими словами, схемы потенциально могут достичь толщины одного атома, но их поведение значительно раньше станет ненадёжным. Большая часть текущей работы Intel по переходу на более тонкие технологические процессы (меньшие транзисторы) состоит в выяснении того, как структурировать отдельные компоненты, чтобы они могли продолжают функционировать как положено.
Суть аргумента Маркова можно понять примерно так: хотя существуют жёсткие физические пределы, они часто не имеют отношения к проблемам, сдерживающим современный полупроводниковый прогресс. Вместо этого, мы сталкиваемся с более мягкими ограничениями, которые зачастую можно обойти. «Когда наступает момент определённого препятствующего прогрессу ограничения, понимание его природы является ключом к его преодолению», пишет он. «Некоторые ограничения можно просто проигнорировать, в то время как другие остаются гипотетическими и основаны только на эмпирических данных; их трудно установить с высокой степенью определённости».
В результате то, что кажется преградами развития, часто преодолевается сочетанием творческого мышления и усовершенствованной технологии. Пример Маркова — дифракционный предел. Первоначально он должен был удержать лазеры на основе аргона-фтора от травления любых структур тоньше 65 нанометров. Но с помощью субволновой дифракции мы в настоящее время работаем над 14 нм структурами, используя этот же лазер.
Где находятся современные пределы?
Марков уделяет внимание двум вопросам, которые считает крупнейшими пределами: энергетика и связь. Вопрос энергопотребления происходит из того, что количество энергии, используемой современными цепями, не сокращается пропорционально уменьшению их физических размеров. Основной результат этого: усилия, сделанные с целью блокировать части чипа в те моменты, когда они не задействованы. Но с нынешними темпами развития данного подхода в каждый конкретный момент времени неактивной является большая часть чипа — отсюда происходит термин «тёмный кремний».
Использование энергии пропорционально рабочему напряжению чипа, а транзисторы просто не могут работать ниже уровня 200 мВ. Сейчас их напряжение в 5 раз выше, так что тут есть простор для снижения. Но прогресс в уменьшении рабочего напряжения замедлился, так что мы снова может прийти к технологическим ограничениям раньше, чем к физическим.
Проблема использования энергии связана с вопросом коммуникации: большая часть физического объёма чипа и большая часть его энергопотребления расходуется на взаимодействие между разными его блоками или остальной частью компьютера. Здесь мы действительно добираемся до физических пределов. Даже если сигналы в чипе двигались бы со скоростью света, чип на частоте выше 5 ГГц не сможет передавать информацию с одной стороны чипа к другому. Лучшее, что мы можем сделать с учётом современных технологий, это попытаться разработать чипы, в которых часто обменивающиеся друг с другом данными блоки были бы физически близко расположены. Включение в уравнение третьего измерения (то есть трёхмерные цепи) могло бы помочь, но лишь незначительно.
Что дальше?
Марков не особенно оптимистичен относительно грядущих изменений. В ближайшей перспективе он ожидает, что использование углеродных нанотрубок для проводки и оптических межсоединений для связи продолжит тенденцию, помогающую нам избежать столкновения с физическими пределами. Однако он отмечает, что обе эти технологии имеют свои собственные ограничения. Углеродные нанотрубки могут быть небольшими, до нанометра в диаметре, но предел размера есть и у них. И фотоны, если они будут использоваться для связи, потребуют аппаратного обеспечения и энергии.
Многие возлагают надежды на квантовые компьютеры, но Марков не один из их поклонников. «Квантовые компьютеры, как цифровые, так и аналоговые, вселяют надежду только в нишевых приложениях и не предлагают значительной производительности в сфере вычислений общего назначения, поскольку не могут быстро выполнять сортировку и другие специфические задачи», утверждает он. Проблема также в том, что это оборудование лучше всего работает при близкой к абсолютному нулю температуре, при комнатной же производительность крайне низкая.
Однако все вычисления в той или иной степени полагаются на квантовые эффекты, и Марков считает, что кое-что полезное из квантовых систем извлечь можно. «Отдельные квантовые устройства приближаются к энергетическим пределам для коммутации, тогда как неквантовые устройства остаются на порядок позади». Очевидно, что получение даже небольшой степени эффективности квантовых систем может сделать большой задел в расходе энергии в пределах всего чипа.
Другой физический предел по Маркову: стирание бита информации имеет термодинамическую стоимость, которую нельзя избежать — вычисления всегда расходуют энергию. Одна из идей для того, чтобы избежать этого предела — «обратимые вычисления», когда компоненты возвращаются в исходное состояние после расчёта. Этот способ может, по крайней мере в теории, позволить получить обратно часть использованной энергии.
Идея эта не является полностью теоретической. Марков цитирует работы с использованием сверхпроводящих цепей (которые он называет «весьма экзотическими»), обеспечивающих обратимое поведение и рассеивание энергии ниже термодинамического предела. Конечно, здесь применяется всего 4 микрокельвина, так что больше энергии тратиться на проверку работоспособности цепей, чем на саму их работу.
За пределами физики
В то время как физика и материаловедение ставят множество ограничений на аппаратную составляющую, математика накладывает ограничения на то, что мы можем с ними сделать. И несмотря на свою репутацию точной науки, математические ограничения намного более расплывчатые, чем физические. Например, до сих пор нет ответа на равенство классов сложности P и NP, несмотря на годы усилий. И хотя мы можем доказать, что некоторые алгоритмы являются наиболее эффективными для общих случаев, легко найти также диапазоны проблем, где альтернативные вычислительные подходы работают лучше.
Самая большая проблема, которую здесь видит Марков, это борьба за извлечение из кода большего параллелизма. Даже дешёвые смартфоны теперь работают на многоядерных процессорах, но до сих пор их использование не оптимально.
В целом складывается впечатление, что главным ограничением является человеческий разум. Хотя Марков не видит на подходе новых фантастических технологий, он оптимистично надеется на устранение текущих препятствий или их обход за счёт прогресса в других областях.
Для адресации операндов в физическом адресном пространстве программы используют логическую адресацию. Процессор автоматически транслирует логические адреса в физические, выдаваемые затем на системную шину.
Архитектура компьютера различает физическое адресное пространство (ФАП) и логическое адресное пространство (ЛАП). Физическое адресное пространство представляет собой простой одномерный массив байтов, доступ к которому реализуется аппаратурой памяти по адресу, присутствующему на шине адреса микропроцессорной системы. Логическое адресное пространство организуется самим программистом исходя из конкретных потребностей. Трансляцию логических адресов в физические осуществляет блок управления памятью MMU.
В архитектуре современных микропроцессоров ЛАП представляется в виде набора элементарных структур: байтов, сегментов и страниц. В микропроцессорах используются следующие варианты организации логического адресного пространства:
- плоское (линейное) ЛАП: состоит из массива байтов, не имеющего определенной структуры; трансляция адреса не требуется, так как логический адрес совпадает с физическим;
- сегментированное ЛАП: состоит из сегментов - непрерывных областей памяти, содержащих в общем случае переменное число байтов; логический адрес содержит 2 части: идентификатор сегмента и смещение внутри сегмента; трансляцию адреса проводит блок сегментации MMU;
- страничное ЛАП: состоит из страниц - непрерывных областей памяти, каждая из которых содержит фиксированное число байтов. Логический адрес состоит из номера (идентификатора) страницы и смещения внутри страницы; трансляция логического адреса в физический проводится блоком страничного преобразования MMU;
- сегментно-страничное ЛАП: состоит из сегментов, которые, в свою очередь, состоят из страниц; логический адрес состоит из идентификатора сегмента и смещения внутри сегмента. Блок сегментного преобразования MMU проводит трансляцию логического адреса в номер страницы и смещение в ней, которые затем транслируются в физический адрес блоком страничного преобразования MMU.
Микропроцессор способен работать в двух режимах: реальном и защищенном.
При работе в реальном режиме возможности процессора ограничены: емкость адресуемой памяти составляет 1 Мбайт, отсутствует страничная организация памяти, сегменты имеют фиксированную длину 216 байт.
Этот режим обычно используется на начальном этапе загрузки компьютера для перехода в защищенный режим.
В реальном режиме сегментные регистры процессора содержат старшие 16 бит физического адреса начала сегмента. Сдвинутый на 4 разряда влево селектор дает 20-разрядный базовый адрес сегмента. Физический адрес получается путем сложения этого адреса с 16-разрядным значением смещения в сегменте, формируемого по заданному режиму адресации для операнда или извлекаемому из регистра EIP для команды (рис. 3.1). По полученному адресу происходит выборка информации из памяти.
Рис. 3.1. Схема получения физического адреса
Наиболее полно возможности микропроцессора по адресации памяти реализуются при работе в защищенном режиме. Объем адресуемой памяти увеличивается до 4 Гбайт, появляется возможность страничного режима адресации. Сегменты могут иметь переменную длину от 1 байта до 4 Гбайт.
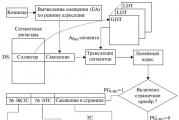
Общая схема формирования физического адреса микропроцессором, работающим в защищенном режиме , представлена на рис. 3.2.
Как уже отмечалось, основой формирования физического адреса служит логический адрес. Он состоит из двух частей: селектора и смещения в сегменте .
Селектор содержится в сегментном регистре микропроцессора и позволяет найти описание сегмента (дескриптор) в специальной таблице дескрипторов. Дескрипторы сегментов хранятся в специальных системных объектах глобальной (GDT) и локальных (LDT) таблицах дескрипторов. Дескриптор играет очень важную роль в функционировании микропроцессора, от формирования физического адреса при различной организации адресного пространства и до организации мультипрограммного режима работы. Поэтому рассмотрим его структуру более подробно.
Сегменты микропроцессора, работающего в защищенном режиме , характеризуются большим количеством параметров. Поэтому в универсальных 32-разрядных микропроцессорах информация о сегменте хранится в

Рис. 3.2. Формирование физического адреса при сегментно-страничной организации памяти
специальной 8-байтной структуре данных, называемой дескриптором , а за сегментными регистрами закреплена основная функция - определение местоположения дескриптора.
Структура дескриптора сегмента представлена на рис. 3.3.

Рис. 3.3. Структура дескриптора сегмента
Мы будем рассматривать именно структуру, а не формат дескриптора, так как при переходе от микропроцессора i286 к 32-разрядному МП расположение отдельных полей дескриптора потеряло свою стройность и частично стало иметь вид "заплаток", поставленных с целью механического увеличения разрядности этих полей.
32-разрядное поле базового адреса позволяет определить начальный адрес сегмента в любой точке адресного пространства в 2 32 байт (4 Гбайт).
Поле предела (limit) указывает длину сегмента (точнее, длину сегмента минус 1: если в этом поле записан 0, то это означает, что сегмент имеет длину 1) в адресуемых единицах, то есть максимальный размер сегмента равен 2 20 элементов.
Величина элемента определяется одним из атрибутов дескриптора битом G (Granularity - гранулярность, или дробность):

Таким образом, сегмент может иметь размер с точностью до 1 байта в диапазоне от 1 байта до 1 Мбайт (при G = 0). При объеме страницы в 2 12 = 4 Кбайт можно задать объем сегмента до 4 Гбайт (приG = l):
Так как в архитектуре IA-32 сегмент может начинаться в произвольной точке адресного пространства и иметь произвольную длину, сегменты в памяти могут частично или полностью перекрываться.
Бит размерности (Default size) определяет длину адресов и операндов, используемых в команде по умолчанию:

своему усмотрению. Конечно, этот бит предназначен не для обычного пользователя, а для системного программиста, применяющего его, например, для отметки сегментов для сбора"мусора" или сегментов, базовые адреса которых нельзя модифицировать. Этот бит доступен только программам, работающим на высшем уровне привилегий. Микропроцессор в своей работе его не меняет и не использует.
Байт доступа определяет основные правила обращения с сегментом.
Бит присутствия P (Present) показывает возможность доступа к сегменту. Операционная система (ОС) отмечает сегмент, передаваемый из оперативной во внешнюю память, как временно отсутствующий, уставливая в его дескрипторе P = 0. При P = 1 сегмент находится в физической памяти. Когда выбирается дескриптор с P = 0 (сегмент отсутствует в ОЗУ), поля базового адреса и предела игнорируются. Это естественно: например, как может идти речь о базовом адресе сегмента, если самого сегмента вообще нет в оперативной памяти? В этой ситуации процессор отвергает все последующие попытки использовать дескриптор в командах, и определяемое дескриптором адресное пространство как бы"пропадает".
Возникает особый случай неприсутствия сегмента. При этом операционная система копирует запрошенный сегмент с диска в память (при этом, возможно, удаляя другой сегмент), загружает в дескриптор базовый адрес сегмента, устанавливает P = 1 и осуществляет рестарт той команды, которая обратилась к отсутствовавшему в ОЗУ сегменту.
Двухразрядное поле DPL (Descriptor Privilege Level) указывает один из четырех возможных (от 0 до 3) уровней привилегий дескриптора , определяющий возможность доступа к сегменту со стороны тех или иных программ (уровень 0 соответствует самому высокому уровню привилегий).
Бит обращения A (Accessed) устанавливается в"1" при любом обращении к сегменту. Используется операционной системой для того, чтобы отслеживать сегменты, к которым дольше всего не было обращений.
Пусть, например, 1 раз в секунду операционная система в дескрипторах всех сегментов сбрасывает бит А. Если по прошествии некоторого времени необходимо загрузить в оперативную память новый сегмент, места для которого недостаточно, операционная система определяет"кандидатов" на то, чтобы очистить часть оперативной памяти, среди тех сегментов, в дескрипторах которых бит А до этого момента не был установлен в"1", то есть к которым не было обращения за последнее время.
Поле типа в байте доступа определяет назначение и особенности использования сегмента. Если бит S (System - бит 4 байта доступа) равен 1, то данный дескриптор описывает реальный сегмент памяти. Если S = 0, то этот дескриптор описывает специальный системный объект, который может и не быть сегментом памяти, например, шлюз вызова, используемый при переключении задач, или дескриптор локальной таблицы дескрипторов LDT. Назначение битов <3...0> байта доступа определяется типом сегмента (рис. 3.4).

Рис. 3.4. Формат поля типа байта доступа
В сегменте кода: бит подчинения, или согласования, C (Conforming) определяет дополнительные правила обращения, которые обеспечивают защиту сегментов программ. При C = 1 данный сегмент является подчиненным сегментом кода. В этом случае он намеренно лишается защиты по привилегиям. Такое средство удобно для организации, например, подпрограмм, которые должны быть доступны всем выполняющимся в системе задачам. При C = 0 - это обычный сегмент кода; бит считывания R (Readable) устанавливает, можно ли обращаться к сегменту только на исполнение или на исполнение и считывание, например, констант как данных с помощью префикса замены сегмента. При R = 0 допускается только выборка из сегмента команд для их выполнения. При R = 1 разрешено также чтение данных из сегмента.
Запись в сегмент кода запрещена. При любой попытке записи возникает программное прерывание.
В сегменте данных:
- ED (Expand Down) - бит направления расширения. При ED = 1 этот сегмент является сегментом стека и смещение в сегменте должно быть больше размера сегмента. При ED = 0 - это сегмент собственно данных (смещение должно быть меньше или равно размеру сегмента);
- бит разрешения записи W(Writeable). При W = 1 разрешено изменение сегмента. При W = 0 запись в сегмент запрещена, при попытке записи в сегмент возникает программное прерывание.
В случае обращения за операндом смещение в сегменте формируется микропроцессором по режиму адресации операнда, заданному в команде. Смещение в сегменте кода извлекается из регистра - указателя команд EIP.
Сумма извлеченного из дескриптора начального адреса сегмента и сформированного смещения в сегменте дает линейный адрес (ЛА).
Если в микропроцессоре используется только сегментное представление адресного пространства, то полученный линейный адрес является также и физическим.
Если помимо сегментного используется и страничный механизм организации памяти, то линейный адрес представляется в виде двух полей: старшие разряды содержат номер виртуальной страницы, а младшие смещение в странице. Преобразование номера виртуальной страницы в номер физической проводится с помощью специальных системных таблиц: каталога таблиц страниц (КТС) и таблиц страниц (ТС). Положение каталога таблиц страниц в памяти определяется системным регистром CR3. Физический адрес вычисляется как сумма полученного из таблицы страниц адреса физической страницы и смещения в странице, полученного из линейного адреса.
Рассмотрим теперь все этапы преобразования логического адреса в физический более подробно.
О том, что с каждым новым поколением литографического техпроцесса становится всё труднее соответствовать так называемому закону Мура, представители Intel не перестают говорить при первом удобном случае. Удвоение количества транзисторов на единице площади микросхемы, которое до сих пор происходило с завидной регулярностью, в будущем может замедлиться, да и сохранение действия закона Мура требует от производителей всё больших материальных затрат, не говоря уже об инженерных ресурсах.
Как признался на организованной институтом IMEC профильной конференции Майк Мэйберри (Mike Mayberry), возглавляющий в Intel направление исследований в сфере компонентов, участники рынка должны пересмотреть концепцию научных разработок в области литографии, чтобы успешно преодолеть очередные физические барьеры на пути повышения производительности микросхем. Комментарии докладчика зафиксировали коллеги с сайта EE Times .
Будущее полупроводниковой промышленности достаточно чётко прогнозируется до момента освоения 10-нм технологии, как сообщает Майк Мэйберри. Компания Intel при помощи имеющихся и ряда перспективных технологий покорит этот рубеж к 2015 году. Однако, по мере уменьшения технологических норм до 7 нм и ниже, возможность применения кремния в качестве одного из основных строительных материалов для выпуска микросхем уже ставится под вопрос. По мнению Мэйберри, участники рынка должны сообща заняться проблемой поиска новых материалов, причём работа должна вестись по нескольким направлениям сразу. Сейчас же все производители полупроводников с разным успехом используют примерно одни и те же идеи. В будущем такая узкая специализация не позволит своевременно выявить новое перспективное направление, которое и будет взято за основу для развития отрасли.
Не только новые материалы (арсенид галлия или германий), но и новые структуры транзисторов будут активно применяться в попытках поиска решений для продолжения выпуска микросхем с всё более "тонкими" технологическими нормами. Наличие альтернатив – это и хорошо, и плохо. Ни одна компания в одиночку подобный объём работ по изучению всех вариантов развития не осилит, а риски сделать ставку "не на ту лошадь" весьма высоки. Мы уже могли наблюдать, как конкурирующие потребители литографического оборудования взялись дружно финансировать ASML. Это доказывает, что ради решения общих проблем участники рынка могут договариваться. В сфере разработки новых литографических технологий подобная консолидация тоже жизненно необходима, сообщает представитель Intel. Денег в этой сфере достаточно, по мнению Мэйберри, нужно лишь правильно расставлять приоритеты в финансировании.
В предыдущем номере еженедельника.
Tипичный персональный компьютер среднего класса содержит от 50 до 70 интегральных схем. Это, прежде всего, микропроцессор - наиболее сложная из схем, выполняющий последовательности команд работы с данными. За 40 лет существования интегральных схем инженерная мысль, естественно, не стояла на месте, и развитие полупроводниковых технологий позволяло уменьшать размеры транзисторов, соответственно увеличивая их количество на микропроцессоре. Несколько штук, затем несколько десятков, несколько десятков тысяч, и, наконец, миллион элементов на интегральной схеме. Не раз исследователи и аналитики предсказывали, что процесс миниатюризации достигнет некоторых физических пределов, которые уже нельзя преодолеть. Однако до сего дня ни одно из предсказаний не сбылось. Высочайшая степень интеграции позволяет год от года наращивать мощность микропроцессоров и на исходе тысячелетия делает возможным выпуск чипов оперативной памяти, способных хранить миллиарды бит данных.
Тем не менее увеличивать быстродействие процессора, сокращая размеры транзисторов, размещаемых на нескольких квадратных сантиметрах кремния, действительно становится все сложнее. Именно сейчас, когда транзистор на процессоре имеет размер порядка двух микрон (это примерно в сто раз меньше ширины человеческого волоса) и может содержать элементы размером в несколько десятых микрона, проблема достижения предела в дальнейшей миниатюризации встает настолько остро, что лаборатории крупнейших научных центров и компаний-производителей серьезно работают над средствами усовершенствования современной технологии производства интегральных схем, а в научных кругах все активнее обсуждается вопрос о возможных альтернативах транзистору вообще как основе вычислительной техники.
Снова о физике
Дальнейшее уменьшение размеров транзистора способно породить ряд физических условий, которые будут препятствовать процессу миниатюризации. В частности, может оказаться чрезвычайно сложным, если вообще возможным, соединение друг с другом мельчайших элементов. Приближение областей проводимости друг к другу на расстояние порядка 100 ангстрем может породить квантовые эффекты, которые поставят под угрозу нормальную работу транзисторов. В лабораториях предел уже достигнут, и ученые исследуют возможные последствия, однако для коммерческого производства в ближайшее десятилетие эта проблема еще не будет актуальна.
Миниатюризация полевого транзистора неизбежно сопровождается усилением электрических полей, что может по-разному влиять на перемещения электронов. В частности, электроны, проходящие через такое сильное электрическое поле, могут приобрести очень большую энергию, и в конечном итоге возникнет лавинообразный электрический ток, способный разрушить схему. Современные процессоры в погоне за все более высокой скоростью обработки уже приближаются к черте, за которой вполне возможно подобное усиление электрических полей. Инженеры прибегают к различным ухищрениям, для того чтобы избежать нежелательных последствий. Разработаны полевые транзисторы, в которых поле может перемещаться в место, где оно не оказывает разрушительного влияния на другие электронные функции. Однако подобные трюки неизбежно требуют компромисса в отношении других характеристик устройства, усложняя разработку и производство или снижая надежность и жизненный цикл транзистора и схемы в целом.
Чем меньше размер транзисторов, тем выше плотность их размещения на процессоре, при этом увеличивается расход тепловой энергии. Сейчас каждый квадратный сантиметр схемы выделяет 30 ватт тепловой энергии - излучение, которое характерно для материала, нагретого до температуры порядка 1200 градусов по Цельсию. Естественно, такие температуры недопустимы в производстве микропроцессоров, поэтому используются различные системы охлаждения для удаления лишнего тепла по мере его возникновения. Стоимость применения этих достаточно мощных систем возрастает с увеличением интенсивности выделяемой тепловой энергии.
Проблемы производства
Помимо чисто физических проблем, процесс уменьшения размеров транзисторов и увеличения степени их интеграции на микропроцессоре может натолкнуться на ограничения, связанные с особенностями производства интегральных схем. Вообще говоря, свойства устройств, которые создаются на одной кремниевой пластине, равно как и на разных пластинах, не идентичны. Отклонения могут возникать на каждом из этапов. Характер вероятных различий между производимыми процессорами и частота появления просто бракованных устройств могут стать реальной преградой на пути дальнейшей миниатюризации элементов интегральной схемы.
Миниатюризация касается не только длины и ширины элемента схемы, но и толщины самого процессора. Транзисторы и соединения на нем реализуются с помощью серии уровней, в современных процессорах их может быть пять или шесть. Уменьшение размеров транзистора и увеличение плотности их размещения на процессоре влечет за собой увеличение числа уровней. Однако чем больше слоев в схеме, тем тщательнее должен быть контроль за ними в процессе производства, поскольку на каждый из уровней будут оказывать влияние нижележащие. Стоимость усовершенствования средств контроля и стоимость создания соединений между множеством уровней могут оказаться фактором, сдерживающим увеличение числа слоев.
Кроме всего прочего, усложнение интегральной схемы потребует совершенствования условий производства, к которым и так предъявляются беспрецедентно высокие требования. Понадобится более точный механический контроль за позиционированием исходной кремниевой пластины. "Стерильное" помещение, где создаются микропроцессоры, должно стать еще стерильнее, дабы исключить попадание мельчайших частичек пыли, способных разрушить сложнейшую схему. С усложнением процессора, повышением степени интеграции элементов на нем возрастет число потенциальных деффектов, и, следовательно, потребуются сверхтщательные процедуры проверки качества. Все это сделает еще более дорогим и без того самое дорогостоящее производство в мире. Но, по мнению одного из изобретателей микропроцессора Гордона Мура, процесс миниатюризации транзисторов остановится, если затраты на увеличение числа элементов на процессоре превысят возможную прибыль от использования таких сложных чипов.
И наконец, важнейшие научные и инженерные разработки ведутся в направлении усовершенствования ключевого этапа производства интегральной схемы - литографии, поскольку именно здесь реально возможно достижение определенного предела уже в обозримом будущем.
Литография - что было, что будет
Развитие литографической технологии со времени ее изобретения в начале 70-х шло в направлении сокращения длины световой волны. Это позволяло уменьшать размеры элементов интегральной схемы. С середины 80-х в фотолитографии используется ультрафиолетовое излучение, получаемое с помощью лазера. Сейчас наиболее мощные коммерческие процессоры производятся с помощью ультрафиолетовых лучей с длиной волны 0,248 мк. Для создания кристаллов гигабитной памяти, то есть интегральных схем с миллиардами транзисторов, разработана литорафическая технология с пульсирующим лазером, которая обеспечивает длину волны 0,193 мк. Однако когда фотолитография перешагнула границу 0,2 мк, возникли серьезные проблемы, которые впервые за историю этой технологии поставили под сомнение возможность ее дальнейшего использования. Например, при длине волны меньше 0,2 мк слишком много света поглощается светочувствительным слоем, поэтому усложняется и замедляется процесс передачи шаблона схемы на процессор.
С другой стороны, для гигабитной памяти потребуются транзисторы с элементами размером 0,18 мк, и использование даже излучения с длиной волны 0,193 мк в принципе недостаточно, так как очень сложно строить структуры схемы, размер которых меньше длины световой волны в литографии. Как заметил один из производителей степперов (машин для фотолитографии), это все равно что рисовать тонкую линию значительно более толстой кистью - способ можно найти, но очень трудно держать его под контролем.
Все эти проблемы побуждают исследователей и производителей искать альтернативы традиционной литографической технологии. Фактически их сейчас три - рентгеновское излучение, электронные лучи и так называемый мягкий рентген (soft x-ray).
Возможность замены ультрафиолетовых лучей рентгеновскими исследуется в научных лабораториях США уже более двух десятилетий. Особую активность проявляла в этом плане компания IBM. Несколько лет назад, объединившись с несколькими фирмами, в том числе с Motorola, компания поставила цель вывести литографию на базе рентгена из лаборатории в производство.
Очень короткая, порядка одного нанометра, длина волны рентгеновского излучения составляет всего четыре сотых длины световых волн, которые используются сейчас для производства наиболее совершенных коммерческих процессоров. Поэтому кажется вполне естественным применение именно этой технологии для создания, скажем, интегральных схем оперативной памяти гигабитного объема. Однако когда дело доходит до анализа реального производства на основе рентгеновской литографии, возникают проблемы, которым пока не найдено адекватного решения. Технология получения рентгеновских лучей принципиально отличается от методов излучения, которые используются в современном производстве интегральных схем. В оптической литографии применяются лазерные установки, а необходимое рентгеновское излучение может быть получено только с помощью специального устройства - синхротрона. И хотя стоимость такого генератора рентгеновских лучей составляет не более 3% общей стоимости самых современных полупроводниковых производств, использование литографии на базе рентгена потребует перепроектирования производства в целом. А это уже совсем другие суммы.
Тем не менее все заметнее активность оппонентов рентгеновской технологии, значительные средства вкладываются в поиски средств усовершенствования традиционных способов литографии; ведется поиск и других способов задания рисунка интегральной схемы на кремниевой пластине.
Интересно, что в процессе производства интегральных схем ежедневно используется технология, с помощью которой в принципе возможно создание мельчайших элементов полупроводникового процессора. Электронно-лучевая (electron beams) литография позволяет сфокусированным пучком ("карандашом") заряженных частиц "рисовать" линии непосредственно на светочусвтвительном слое. Этот метод сейчас используется для прорисовки шаблонов схемы на фотолитографической маске. И в течение тех же 20 лет ученые лелеют надежду перенести технологию электронных лучей в процесс создания самой схемы. Однако электронные лучи - слишком медленный способ для данной задачи: электронный "карандаш" рисует каждый элемент процессора отдельно, поэтому на обработку одной схемы может уйти несколько часов, что недопустимо при массовом производстве. С середины 80-х в Bell Labs ведутся исследования сканирования широкого электронного луча по схеме. Как и в фотолитографии, этот метод использует проектирование лучей через маску и уменьшение изображения на маске с помощью линз. По оценкам ряда исследователей, в долгосрочной перспективе именно технология сканирования электронных лучей может стать наиболее реальной заменой традиционной литографии.
Поиск альтернативы транзисторам
В конце концов, компьютер - устройство физическое, и его базовые операции описываются законами физики. А с физической точки зрения тот тип транзистора, который является основой современной интегральной схемы, может быть уменьшен еще примерно в 10 раз, до размера в 0,03 мк. За этой гранью процесс включения/выключения микроскопических переключателей станет практически невозможным. Поведение транзисторов будет похоже на текущие краны - перемещение электрона с одного конца на другой выйдет из-под контроля.
Как уже говорилось, предел миниатюризации элементов процессора может наступить и раньше из-за различных физических и производственных проблем. Поэтому некоторые ученые формулируют задачу однозначно - найти физическую замену основе основ. Не транзистор, передающий и усиливающий электрический сигнал под действием поля, а нечто другое. Но что? Физики утверждают, например, что на определенном этапе миниатюризации элементы схемы станут настолько малы, что их поведение нужно будет описывать законами квантовой механики. В начале 80-х исследователи одной из научных лабораторий США показали, что компьютер в принципе может функционировать по квантово-механическим законам. В таком квантовом компьютере для хранения информации могут использоваться, например, атомы водорода, различные энергетические состояния которых будут соответствовать 0 и 1. Ученые ищут способы реализации квантовой логики. В нынешнем десятилетии в ряде научных центров США велись и ведутся достаточно активные работы по созданию архитектурных принципов квантовых компьютеров. Пока неясно, смогут ли (и насколько эффективно) машины, использующие совершенно иные физические принципы работы, решать традиционные математические задачи и тем более опередить в этом своих классических конкурентов. Однако продвигаются идеи о полезности квантовых компьютеров при моделировании именно квантовых физических систем.
Предлагаются и другие альтернативы транзистору, например нелинейные оптические устройства, в которых электрические токи и напряжения заменяет интенсивность оптических лучей. Реализация этой идеи связана с рядом проблем. Особенно важно, что, в отличие от электричества, свет плохо взаимодействует со светом, а взаимодействие сигналов - необходимое условие для реализации логических функций.
Не приходится пока говорить о перспективах массового производства квантовых или оптических компьютеров. Поэтому будущее (по крайней мере обозримое) компьютерной техники будет по-прежнему связано с транзисторами. Вполне возможно, что те реальные проблемы, которые встают на пути дальнейшего их уменьшения и о которых мы попытались дать представление нашему читателю, приведут к замедлению процесса появления новых поколений схем памяти и микропроцессоров, которые сейчас возникают с периодичностью примерно раз в три года. Разработчики будут искать другие пути повышения производительности процессоров, не связанные непосредственно с уменьшением компонентов интегральных схем. Например, увеличение размеров процессора позволит разместить на нем большее число транзисторов. Кристалл может стать "толще" - за счет увеличения числа горизонтальных уровней схемы можно повысить плотность размещения элементов памяти или логических устройств, не меняя их размера. А может быть, барьеры на пути создания еще более мощных и умных машин будут преодолены с помощью необыкновенно умного и мощного ПО, которое подчиняется уже совсем другим, отнюдь не физическим законам.
Как это делается
Процесс производства микосхемы можно разбить на несколько этапов
1. Разработка микропроцессора. На квадратной кремниевой пластинке размером с ноготь ребенка необходимо построить схему из миллионов транзисторов, при этом их расположение и соединения между ними должны быть разработаны заранее и с предельной тщательностью. Каждый транзистор в схеме выполняет определенную функцию, группа транзисторов комбинируется таким образом, чтобы реализовать определенный элемент схемы. Разработчик должен также учитывать назначение данного кристалла. Структура процессора, выполняющего команды, будет отличаться от интегральной схемы памяти, которая хранит данные. Поскольку современные микропроцессоры имеют очень сложную структуру, их разработка ведется с помощью компьютера.
2. Создание кремниевой пластины. Базовым материалом для построения интегральной схемы выбран кристалл кремния, одного из самых распространенных на земле элементов с естественными свойствами полупроводника. Для производства микропроцессора выделенный из кварца кремний подвергается химической обработке. Из полученного в результате 100-процентного кремния путем переплавки формируют цилиндрический слиток, который затем разрезается на пластины толщиной менее миллиметра. Пластина полируется до тех пор, пока не будет получена абсолютно гладкая, зеркальная поверхность. Кремниевые пластины, как правило, имеют диаметр 200 мм, однако уже в ближайшее время планируется перейти на стандарт диаметра 300 мм. Поскольку на одной пластине размещаются сотни микропроцессоров, увеличение диаметра позволит увеличить число схем, которые производятся за один раз, и, следовательно, снизить стоимость одного процессора.
3. Создание начальных уровней. После того как подготовлена кремниевая пластина, начинается непосредственно процесс создания интегральной схемы. Транзисторы и соединения между ними реализуются за несколько базовых этапов, последовательность которых повторяется множество раз. Наиболее сложные микропроцессоры могут включать более 20 уровней, и для их создания требуется предпринять несколько сотен производственных шагов.
Прежде всего над кремниевой основой чипа создается уровень изолятора - двуокись кремния. Для этого пластина помещается в специальную печь, в которой на ее поверх-
ности наращивается тонкий слой изолятора. Затем пластина подготавливается к первому наложению шаблона схемы. С помощью специальной машины поверхность пластины равномерно покрывается светочувствительным полимерным веществом, которое под действием ультрафиолетовых лучей приобретает способность растворяться.
4. Фотолитография (маскирование). Для того чтобы нанести рисунок схемы на пластину, с помощью управляемой компьютером машины (степпера) выполняется фотолитография - процесс пропускания ультрафиолетовых лучей через маску. Сложная система линз уменьшает заданный на маске шаблон до микроскопических размеров схемы. Кремниевая пластина закрепляется на позиционном столе под системой линз и перемещается с его помощью таким образом, чтобы были последовательно обработаны все размещенные на пластине микропроцессоры. Ультрафиолетовые лучи от дуговой лампы или лазера проходят через свободные пространства на маске. Под их действием светочувствительный слой в соответствующих местах пластины приобретает способность к растворению и затем удаляется органическими растворителями.
5. Травление. На этом этапе оставшийся светочувствительный слой защищает нижележащий уровень изолятора от удаления при обработке кислотой (или реактивным газом), с помощью которой рисунок схемы протравливается на поверхности пластины. Затем этот защитный светочувствительный уровень удаляется.
6. Создание дополнительных уровней. Дальнейшие процессы маскирования и травления определяют размещение дополнительных материалов на поверхности пластины, таких как проводящий поликристаллический кремний, а также различные оксиды и металлы. В результате на кремниевой пластине создается необходимая комбинация проводящих и непроводящих областей, которая на следующем этапе позволит реализовать транзисторы в интегральной схеме.
7. Осаждение примесей. На этом этапе к кремнию на пластине в определенных местах добавляются примеси, такие как бор или мышьяк, которые позволяют изменить способ передачи электрического тока полупроводником. Базовый материал микропроцессора - это кремний с p-проводимостью. Во время травления в нужных местах удаляются нанесенные ранее на базовый кремний слои проводника (поликристаллического кремния) и изолятора (двуокиси кремния), так чтобы оставлять открытыми две полосы р-области, разделенные полосой с неудаленными изолятором и проводником (затвор будущего транзистора). Добавление примесей преобразует верхний уровень р-областей в n-области, формируя исток и сток транзистора. Выполненные многократно, эти операции позволяют создать огромное количество транзисторов, необходимых для реализации микропроцессора. Следующая задача - соединить их между собой, для того чтобы интегральная схема могла выполнять свои функции.
8. Соединения. Очередные операции маскирования и травления открывают области электрических контактов между различными уровнями чипа. Затем на пластину осаждается слой алюминия и на его основе с помощью фотолитографии формируется схема соединений между всеми транзисторами на микропроцессоре.
На этом обработка исходной кремниевой пластины завершается. Затем каждый процессор на пластине подвергается тщательной проверке на правильность функционирования его электрических соединений, после чего специальная машина разрезает пластину на отдельные интегральные схемы. Качественные процессоры отделяются от бракованных и могут использоваться по назначению.