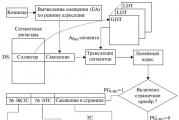
Компания мехатроника. Эффективные кластерные решения
Данная страница написана с таким расчетом, чтобы она могла быть полезной не только пользователям вычислительных кластеров НИВЦ, но и всем, желающим получить представление о работе вычислительного кластера. Решение типичных проблем пользователей кластера НИВЦ изложено на отдельной странице.
Что такое вычислительный кластер?
В общем случае, вычислительный кластер - это набор компьютеров (вычислительных узлов), объединенных некоторой коммуникационной сетью. Каждый вычислительный узел имеет свою оперативную память и работает под управлением своей операционной системы. Наиболее распространенным является использование однородных кластеров, то есть таких, где все узлы абсолютно одинаковы по своей архитектуре и производительности.
Подробнее о том, как устроен и работает вычислительный кластер можно почитать в книге А.Лациса "Как построить и использовать суперкомпьютер" .
Как запускаются программы на кластере?
Для каждого кластера имеется выделенный компьютер - головная машина (front-end). На этой машине установлено программное обеспечение, которое управляет запуском программ на кластере. Собственно вычислительные процессы пользователей запускаются на вычислительных узлах, причем они распределяются так, что на каждый процессор приходится не более одного вычислительного процесса. Запускать вычислительные процессы на головной машине кластера нельзя.
Пользователи имеют терминальный доступ на головную машину кластера, а входить на узлы кластера для них нет необходимости. Запуск программ на кластере осуществляется в т.н. "пакетном" режиме - это значит, что пользователь не имеет непосредственного, "интерактивного" взаимодействия с программой, программа не может ожидать ввода данных с клавиатуры и выводить непосредственно на экран. Более того, программа пользователя может работать тогда, когда пользователь не подключен к кластеру.
Какая установлена операционная система?
Вычислительный кластер, как правило, работает под управлением одной из разновидностей ОС Unix - многопользовательской многозадачной сетевой операционной системы. В частности, в НИВЦ МГУ кластеры работают под управлением ОС Linux - свободно распространяемого варианта Unix. Unix имеет ряд отличий от Windows, которая обычно работает на персональных компьютерах, в частности эти отличие касаются интерфейса с пользователем, работы с процессами и файловой системы.
Более подробно об особенностях и командах ОС UNIX можно почитать здесь:
- Инсталляция Linux и первые шаги (книга Matt Welsh, перевод на русский язык А.Соловьева).
- Операционная система UNIX (информационно-аналитические материалы на сервере CIT-Forum).
Как хранятся данные пользователей?
Все узлы кластера имеют доступ к общей файловой системе, находящейся на файл-сервере. То есть файл может быть создан, напрмер, на головной машине или на каком-то узле, а затем прочитан под тем же именем на другом узле. Запись в один файл одновременно с разных узлов невозможна, но запись в разные файлы возможна. Кроме общей файловой системы, могут быть локальные диски на узлах кластера. Они могут использоваться программами для хранения временных файлов. После окончания (точнее, непосредственно перед завершением) работы программы эти файлы должны удаляться.
Какие используются компиляторы?
Никаких специализированных параллельных компиляторов для кластеров не существует. Используются обычные оптимизирующие компиляторы с языков Си и Фортран - GNU, Intel или другие, умеющие создавать исполняемые программы ОС Linux. Как правило, для компиляции параллельных MPI-программ используются специальные скрипты (mpicc, mpif77, mpif90 и др.), которые являются надстройками над имеющимися компиляторами и позволяют подключать необходимые библиотеки.
Как использовать возможности кластера?
Существует несколько способов задействовать вычислительные мощности кластера.
1. Запускать множество однопроцессорных задач. Это может быть разумным вариантом, если нужно провести множество независимых вычислительных экспериментов с разными входными данными, причем срок проведения каждого отдельного расчета не имеет значения, а все данные размещаются в объеме памяти, доступном одному процессу.
2. Запускать готовые параллельные программы. Для некоторых задач доступны бесплатные или коммерческие параллельные программы, которые при необходимости Вы можете использовать на кластере. Как правило, для этого достаточно, чтобы программа была доступна в исходных текстах, реализована с использованием интерфейса MPI на языках С/C++ или Фортран. Примеры свободно распространяемых параллельных программ, реализованных с помощью MPI: GAMESS-US (квантовая химия), POVRay-MPI (трассировка лучей).
3. Вызывать в своих программах параллельные библиотеки. Также для некоторых областей, таких как линейная алгебра, доступны библиотеки, которые позволяют решать широкий круг стандартных подзадач с использованием возможностей параллельной обработки. Если обращение к таким подзадачам составляет большую часть вычислительных операций программы, то использование такой параллельной библиотеки позволит получить параллельную программу практически без написания собственного параллельного кода. Примером такой библиотеки является SCALAPACK. Русскоязычное руководство по использованию этой библиотеки и примеры можно найти на сервере по численному анализу НИВЦ МГУ. Также доступна параллельная библиотека FFTW для вычисления быстрых преобразований Фурье (БПФ). Информацию о других параллельных библиотеках и программах, реализованных с помощью MPI, можно найти по адресу http://www-unix.mcs.anl.gov/mpi/libraries.html .
4. Создавать собственные параллельные программы. Это наиболее трудоемкий, но и наиболее универсальный способ. Существует два основных варианта. 1) Вставлять параллельные конструкции в имеющиеся параллельные программы. 2) Создавать "с нуля" параллельную программу.
Как работают параллельные программы на кластере?
Параллельные программы на вычислительном кластере работают в модели передачи сообщений (message passing). Это значит, что программа состоит из множества процессов, каждый из которых работает на своем процессоре и имеет свое адресное пространство. Причем непосредственный доступ к памяти другого процесса невозможен, а обмен данными между процессами происходит с помощью операций приема и посылки сообщений. То есть процесс, который должен получить данные, вызывает операцию Receive (принять сообщение), и указывает, от какого именно процесса он должен получить данные, а процесс, который должен передать данные другому, вызывает операцию Send (послать сообщение) и указывает, какому именно процессу нужно передать эти данные. Эта модель реализована с помощью стандартного интерфейса MPI. Существует несколько реализаций MPI, в том числе бесплатные и коммерческие, переносимые и ориентированные на конкретную коммуникационную сеть.
Как правило, MPI-программы построены по модели SPMD (одна программа - много данных), то есть для всех процессов имеется только один код программы, а различные процессы хранят различные данные и выполняют свои действия в зависимости от порядкового номера процесса.
- Лекция 5. Технологии параллельного программирования. Message Passing Interface .
- Вычислительный практикум по технологии MPI (А.С.Антонов).
- А.С.Антонов .
- MPI: The Complete Reference (на англ.яз.).
- Глава 8: Message Passing Interface в книге Яна Фостера "Designing and Building Parallel Programs" (на англ.яз.).
Где можно посмотреть примеры параллельных программ?
Схематичные примеры MPI-программ можно посмотреть здесь:
- Курс Вл.В.Воеводина "Параллельная обработка данных". Приложение к лекции 5 .
- Примеры из пособия А.С.Антонова "Параллельное программирование с использованием технологии MPI" .
Можно ли отлаживать параллельные программы на персональном компьютере?
Разработка MPI-программ и проверка функциональности возможна на обычном ПК. Можно запускать несколько MPI-процессов на однопроцессорном компьютере и таким образом проверять работоспособность программы. Желательно, чтобы это был ПК с ОС Linux, где можно установить пакет MPICH . Это возможно и на компьютере с Windows, но более затруднительно.
Насколько трудоемко программировать вычислительные алгоритмы c помощью MPI и есть ли альтернативы?
Набор функций интерфейса MPI иногда называют "параллельным ассемблером", т.к. это система программирования относительно низкого уровня. Для начинающего пользователя-вычислителя может быть достаточно трудоемкой работой запрограммировать сложный параллельный алгоритм с помощью MPI и отладить MPI-программу. Существуют и более высокоуровневые системы программирования, в частности российские разработки - DVM и НОРМА , которые позволяют пользователю записать задачу в понятных для него терминах, а на выходе создают код с использованием MPI, и поэтому могут быть использованы практически на любом вычислительном кластере.
Как ускорить проведение вычислений на кластере?
Во-первых, нужно максимально ускорить вычисления на одном процессоре, для чего можно принять следующие меры.
1. Подбор опций оптимизации компилятора. Подробнее об опциях компиляторов можно почитать здесь:
- Компиляторы Intel C++ и Fortran (русскоязычная страница на нашем сайте).
2. Использование оптимизированных библиотек. Если некоторые стандартные действия, такие как умножение матриц, занимают значительную долю времени работы программы, то имеет смысл использовать готовые оптимизированные процедуры, выполняющие эти действия, а не программировать их самостоятельно. Для выполнения операций линейной алгебры над матричными и векторными величинами была разработана библиотека BLAS ("базовые процедуры линейной алгебры"). Интерфейс вызова этих процедур стал уже фактически стандартом и сейчас существуют несколько хорошо оптимизированных и адаптированных к процессорным архитектурам реализаций этой библиотеки. Одной из таких реализаций является свободно распространяемая библиотека , которая при установке настраивается с учетом особенностей процессора. Компания Интел предлагает библиотеку MKL - оптимизированную реализацию BLAS для процессоров Intel и SMP-компьютеров на их основе. статья про подбор опций MKL.
Подробнее о библиотеках линейной алгебры (BLAS) можно почитать здесь:
3. Исключение своппинга (автоматического сброса данных из памяти на диск). Каждый процесс должен хранить не больше данных, чем для него доступно оперативной памяти (в случае двухпроцессорного узла это примерно половина от физической памяти узла). В случае необходимости работать с большим объемом данных может быть целесообразным организовать работу со временными файлами или использовать несколько вычислительных узлов, которые в совокупности предоставляют необходимый объем оперативной памяти.
4. Более оптимальное использование кэш-памяти. В случае возможности изменять последовательность действий программы, нужно модифицировать программу так, чтобы действия над одними и те же или подряд расположенными данными данными выполнялись также подряд, а не "в разнобой". В некоторых случаях может быть целесообразно изменить порядок циклов во вложенных циклических конструкциях. В некоторых случаях возможно на "базовом" уровне организовать вычисления над такими блоками, которые полностью попадают в кэш-память.
5. Более оптимальная работа с временными файлами. Например, если программа создает временные файлы в текущем каталоге, то более разумно будет перейти на использование локальных дисков на узлах. Если на узле работают два процесса и каждый из них создает временные файлы, и при этом на узле доступны два локальных диска, то нужно, чтобы эти два процесса создавали файлы на разных дисках.
6. Использование наиболее подходящих типов данных. Например, в некоторых случаях вместо 64-разрядных чисел с плавающей точкой двойной точности (double) может быть целесообразным использовать 32-разрядные числа одинарной точности (float) или даже целые числа (int).
Более подробно о тонкой оптимизации программ можно почитать в руководстве по оптимизации для процессоров Intel и в других материалах по этой теме на веб-сайте Intel.
Как оценить и улучшить качество распараллеливания?
Для ускорения работы параллельных программ стоит принять меры для снижения накладных расходов на синхронизацию и обмены данными. Возможно, приемлемым подходом окажется совмещение асинхронных пересылок и вычислений. Для исключения простоя отдельных процессоров нужно наиболее равномерно распределить вычисления между процессами, причем в некоторых случаях может понадобиться динамическая балансировка.
Важным показателем, который говорит о том, эффективно ли в программе реализован параллелизм, является загрузка вычислительных узлов, на которых работает программа. Если загрузка на всех или на части узлов далека от 100% - значит, программа неэффективно использует вычислительные ресурсы, т.е. создает большие накладные расходы на обмены данными или неравномерно распределяет вычисления между процессами. Пользователи НИВЦ МГУ могут посмотреть загрузку через веб-интерфейс для просмотра состояния узлов.
В некоторых случаях для того, чтобы понять, в чем причина низкой производительности программы и какие именно места в программе необходимо модифицировать, чтобы добиться увеличения производительности, имеет смысл использовать специальные средства анализа производительности - профилировщики и трассировщики.
Подробнее об улучшении производительности параллельных программ можно почитать в книге В.В.Воеводина и Вл.В.Воеводина
Кластерные вычислительные системы стали продолжением развития идей, заложенных в архитектуре MPA-систем. Если в MPAсистеме в качестве законченного вычислительного узла выступает процессорный модуль, то в кластерных системах в качестве таких вычислительных узлов используют серийно выпускаемые компьютеры. Развитие коммуникационных технологий, а именно, появление высокоскоростного сетевого оборудования и специальных программных библиотек, например, MPI (Message Passing Interface), реализующих механизм передачи сообщений по стандартным сетевым протоколам, сделали кластерные технологии общедоступными. В настоящее время создается множество небольших кластерных систем посредством объединения вычислительных мощностей компьютеров лаборатории или учебного класса.
Привлекательной чертой кластерных технологий является то, что для достижения необходимой производительности они позволяют строить гетерогенные системы, т. е. объединять в единые вычислительные системы компьютеры самого разного типа, начиная от персональных компьютеров и заканчивая мощными суперкомпьютерами. Широкое распространение кластерные технологии получили как средство создания систем суперкомпьютерного класса из составных частей массового производства, что значительно удешевляет стоимость вычислительной системы. В частности, одним из первых в 1998 году был реализован проект The COst effective COmputing Array (COCOA), в котором на базе 25 двухпроцессорных персональных компьютеров общей стоимостью порядка 100000 долларов была создана система с производительностью, эквивалентной 48-процессорному Cray T3D стоимостью несколько миллионов долларов.
Лайал Лонг (Lyle Long), профессор аэрокосмической инженерии в университете штата Пенсильвания (Penn State University), считает, что относительно дешевые кластерные вычислительные системы вполне могут служить альтернативой дорогим суперкомпьютерам в научных организациях. Под его руководством в университете был построен кластер COCOA. В рамках данного проекта объединены 25 ра-
бочих станций от DELL, каждая из которых включает два процессора Pentium II/400 МГц, 512 МБ оперативной памяти, 4-гигабайтный жесткий диск SCSI и сетевой адаптер Fast Ethernet. Для связи узлов используется 24-портовый коммутатор Baynetworks 450T с одним модулем расширения. Установленное программное обеспечение включает операционную систему RedHat Linux, компиляторы Fortran 90 и HPF от Portland Group, свободно распространяемую реализацию MPI - Message Passing Interface Chameleon (MPICH) и систему поддержки очередей DQS.
В работе, представленной на 38-й конференции Aerospace Science Meeting and Exhibit, Лонг описывает параллельную версию расчетной программы с автоматическим распределением вычислительной нагрузки, используемой для предсказания уровня шума от вертолетов в различных точках. Для сравнения данная расчетная программа была запущена на трех различных 48-процессорных компьютерах для расчета шума в 512 точках. На системе Cray T3E расчет занял 177 секунд, на системе SGI Origin2000 - 95 секунд, а на кластере COCOA - 127 секунд. Таким образом, кластеры являются очень эффективной вычислительной платформой для задач такого класса.
Преимущество кластерных систем перед суперкомпьютерами состоит еще и в том, что их владельцам не приходится делить процессорное время с другими пользователями, как в крупных суперкомпьютерных центрах. В частности, COCOA обеспечивает более 400 тысяч часов процессорного времени в год, тогда как в суперкомпьютерных центрах бывает трудно получить 50 тысяч часов.
Конечно, о полной эквивалентности этих систем говорить не приходится. Как известно, производительность систем с распределенной памятью очень сильно зависит от производительности коммутационной среды, которую можно охарактеризовать двумя параметрами: латентностью - временем задержки при посылке сообщения, и пропускной способностью - скоростью передачи информации. Например, для компьютера Cray T3D эти параметры составляют соответственно 1 мкс и 480 Мб/с, а для кластера, в котором в качестве коммутационной среды использована сеть Fast Ethernet, - 100 мкс и 10 Мб/с. Это отчасти объясняет очень высокую стоимость суперкомпьютеров. При таких параметрах, как у рассматриваемого кластера, найдется не так много задач, которые могут эффективно решаться на достаточно большом числе процессоров.
На основе вышеизложенного дадим определение: кластер - это связанный набор полноценных компьютеров, используемый в качестве единого вычислительного ресурса. В качестве узлов кластеров могут использоваться как одинаковые (гомогенные кластеры), так и разные (гетерогенные кластеры) вычислительные машины. По своей архитектуре кластерная вычислительная система является слабосвязанной. Для создания кластеров обычно используются либо простые однопроцессорные персональные компьютеры, либо двухили четырехпроцессорные SMP-серверы. При этом не накладывается никаких ограничений на состав и архитектуру узлов. Каждый из узлов может функционировать под управлением своей собственной операционной системы. Чаще всего используются стандартные операционные системы Linux, FreeBSD, Solaris, Tru64 Unix, Windows NT.
В литературе отмечают четыре преимущества, достигаемые с помощью кластеризации вычислительной системы:
∙ абсолютная масштабируемость;
∙ наращиваемая масштабируемость;
∙ высокий коэффициент готовности;
∙ соотношение цена/производительность.
Поясним каждую из перечисленных выше особенностей кластерной вычислительной системы.
Свойство абсолютной масштабируемости означает, что возможно создание больших кластеров, превосходящих по вычислительной мощности даже самые производительные одиночные вычислительные машины. Кластер может содержать десятки узлов, каждый из которых представляет собой мультипроцессор.
Свойство наращиваемой масштабируемостиозначает, что кластер можно наращивать, добавляя новые узлы небольшими порциями. Таким образом, пользователь может начать с малой системы, расширяя ее по мере необходимости.
Поскольку каждый узел кластера - самостоятельная вычислительная машина или система, отказ одного из узлов не приводит к потере работоспособности кластера. Во многих системах отказоустойчивость автоматически поддерживается программным обеспечением.
И наконец, кластерные системы обеспечивают недостижимое для суперкомпьютеров соотношение цена/качество . Кластеры любой производительности можно создать, используя стандартные «строительные блоки», при этом стоимость кластера будет ниже, чем оди-
ночной вычислительной машины с эквивалентной вычислительной мощностью.
Таким образом, на аппаратном уровне кластер - совокупность независимых вычислительных систем, объединенных сетью. Решения могут быть простыми, основывающимися на аппаратуре Ethernet, или сложными с высокоскоростными сетями с пропускной способностью в сотни мегабайтов в секунду.
Неотъемлемая часть кластера - специализированное ПО, на которое возлагается задача поддержания вычислений при отказе одного или нескольких узлов. Такое ПО производит перераспределение вычислительной нагрузки при отказе одного или нескольких узлов кластера, а также восстановление вычислений при сбое в узле. Кроме того, при наличии в кластере совместно используемых дисков кластерное ПО поддерживает единую файловую систему.
Классификация архитектур кластерных систем
В литературе описываются различные способы классификации кластерных систем. Простейшая классификация основана на способе использования дисковых массивов: совместно либо раздельно.
На рис. 5.5.1 и5.5.2 приведены структуры кластеров из двух узлов, координация работы которых обеспечивается высокоскоростной линией, используемой для обмена сообщениями. Это может быть локальная сеть, применяемая также и не входящими в кластер компьютерами, либо выделенная линия. В случае выделенной линии один или несколько узлов кластера будут иметь выход на локальную или глобальную сеть, благодаря чему обеспечивается связь между серверным кластером и удаленными клиентскими системами.
Различие между представленными кластерами заключается в том, что в случае локальной сети узлы используют локальные дисковые массивы, а в случае выделенной линии узлы совместно используют один избыточный массив независимых жестких дисков или так называемый RAID (Redundant Array of Independent Disks). RAID состоит из нескольких дисков, управляемых контроллером, взаимосвязанных скоростными каналами и воспринимаемых внешней системой как единое целое. В зависимости от типа используемого массива могут обеспечиваться различные степени отказоустойчивости и быстродействия.
Процессор | Процессор | Высокоскоростная | Процессор | Процессор | |||||||||||||||||||||||||||
магистраль | |||||||||||||||||||||||||||||||
Устройство | Устройство | Устройство | Устройство | ||||||||||||||||||||||||||||
ввода/вывода | ввода/вывода | ввода/вывода | ввода/вывода | ||||||||||||||||||||||||||||
Дисковый | Дисковый | ||||||||||||||||||||||||||||||
Рис. 5.5.1. Конфигурация кластера без совместно используемых дисков

Дисковый
Устройство | Устройство | ||||||||||||||||||||||||||
Процессор | Процессор | ввода/вывода | ввода/вывода | Процессор | Процессор |
||||||||||||||||||||||
Устройство | Устройство | Устройство | Устройство | ||||||||||||||||||||||||
ввода/вывода | ввода/вывода | ввода/вывода | ввода/вывода | ||||||||||||||||||||||||
Дисковый | Высокоскоростная | Дисковый | |||||||||||||||||||||||||
магистраль | |||||||||||||||||||||||||||
Рис. 5.5.2. Конфигурация кластера с совместно используемыми дисками
Рассмотрим наиболее распространенные типы дисковых масси-
RAID0 (striping - чередование) - дисковый массив из двух или более жестких дисков с отсутствием резервирования. Информация разбивается на блоки данных и записывается на оба (несколько) дисков одновременно. Достоинство - существенное повышение производительности. Недостаток - надежность RAID0 заведомо ниже надежности любого из дисков в отдельности и снижается с увеличением количества входящих в RAID0 дисков, так как отказ любого из дисков приводит к неработоспособности всего массива.
RAID1 (mirroring - зеркалирование) - массив, состоящий как минимум из двух дисков. Достоинствами являются приемлемая скорость записи и выигрыш в скорости чтения при распараллеливании запросов, а также высокая надежность: работает до тех пор, пока функционирует хотя бы один диск в массиве. Вероятность выхода из строя сразу двух дисков равна произведению вероятностей отказа каждого диска. На практике при выходе из строя одного из дисков следует срочно принимать меры: вновь восстанавливать избыточность. Для этого с любым уровнем RAID (кроме нулевого) рекомендуют использовать диски горячего резерва. Достоинство такого подхода - поддержание постоянной доступности. Недостаток заключается в том, что приходится оплачивать стоимость двух жестких дисков, получая полезный объем одного жесткого диска.
RAID10 - зеркалированный массив, данные в котором записываются последовательно на несколько дисков, как в RAID0. Эта архитектура представляет собой массив типа RAID0, сегментами которого вместо отдельных дисков являются массивы RAID1. Соответственно, массив этого уровня должен содержать как минимум четыре диска. RAID10 сочетает высокую отказоустойчивость и производительность.
Более полное представление о кластерных вычислительных системах дает классификация кластеров по используемым методам кластеризации, которые определяют основные функциональные особенности системы:
∙ кластеризация с пассивным резервированием;
∙ кластеризация с активным резервированием;
∙ самостоятельные серверы;
∙ серверы с подключением ко всем дискам;
∙ серверы с совместно используемыми дисками.
Кластеризация с резервированием - наиболее старый и универсальный метод. Один из серверов берет на себя всю вычислительную нагрузку, в то время как другой остается неактивным, но готовым принять вычисления при отказе основного сервера. Активный (или первичный) сервер периодически посылает резервному (вторичному) серверу тактирующее сообщение. При отсутствии тактирующих сообщений, что рассматривается как отказ первичного сервера, вторичный сервер берет управление на себя. Такой подход повышает коэффициент готовности, но не улучшает производительности. Более того, если единственный вид общения между узлами - обмен сообщениями, и если оба сервера кластера не используют диски совместно, то резервный сервер не имеет доступа к базам данных, управляемым первичным сервером.
Пассивное резервирование для кластеров нехарактерно. Термин «кластер» относят ко множеству взаимосвязанных узлов, активно участвующих в вычислительном процессе и совместно создающих иллюзию одной мощной вычислительной машины. К такой конфигурации обычно применяют понятие системы с активным вторичным сервером, и здесь выделяют три метода кластеризации: самостоятельные серверы, серверы без совместного использования дисков и серверы с совместным использованием дисков.
В первом методе каждый узел кластера рассматривается как самостоятельный сервер с собственными дисками, причем ни один из дисков в системе не является совместно используемым. Схема обеспечивает высокую производительность и высокий коэффициент готовности, однако требует специального ПО для планирования распределения запросов клиентов по серверам так, чтобы добиться сбалансированного и эффективного использования всех серверов. Необходимо, чтобы при отказе одного из узлов в процессе выполнения какого-либо приложения другой узел кластера мог перехватить и завершить это приложение. Для этого данные в системе должны постоянно копироваться, чтобы каждый сервер имел доступ ко всем наиболее свежим данным в системе. Из-за этих издержек высокий коэффициент готовности обеспечивается лишь за счет потери производительности.
Для сокращения коммуникационных издержек большинство кластеров в настоящее время состоят из серверов, подключенных к общим дискам, обычно представленных дисковым массивом RAID (см. рис. 5.5.2 ).
Один из вариантов такого подхода предполагает, что совместное использование дисков не применяется. Общие диски разбиваются на разделы, и каждому узлу кластера выделяется свой раздел. Если один из узлов отказывает, кластер может быть реконфигурирован так, что права доступа к его разделу общего диска передаются другому узлу.
При другом варианте множество серверов разделяют во времени доступ к общим дискам, так что любой узел имеет доступ ко всем разделам всех общих дисков. Такой подход требует наличия каких-либо средств блокировки, гарантирующих, что в любой момент времени доступ к данным будет иметь только один из серверов.
Кластеры обеспечивают высокий уровень доступности - в них отсутствуют единая операционная система и совместно используемая память, т. е. нет проблемы когерентности кэш-памяти. Кроме того, специальное ПО в каждом узле постоянно контролирует работоспособность всех остальных узлов. Этот контроль основан на периодической рассылке каждым узлом сигнала «Я еще бодрствую». Если сигнал от некоторого узла не поступает, то такой узел считается вышедшим из строя; ему не предоставляется возможность выполнять ввод/вывод, его диски и другие ресурсы (включая сетевые адреса) переназначаются другим узлам, а выполнявшиеся в нем программы перезапускаются в других узлах.
Производительность кластеров хорошо масштабируется при добавлении узлов. В кластере может выполняться несколько отдельных приложений, но для масштабирования отдельного приложения требуется, чтобы его части взаимодействовали путем обмена сообщениями. Однако нельзя не учитывать, что взаимодействия между узлами кластера занимают гораздо больше времени, чем в традиционных вычислительных системах. Возможность практически неограниченного наращивания числа узлов и отсутствие единой операционной системы делают кластерные архитектуры исключительно хорошо масштабируемыми. Успешно используются системы с сотнями и тысячами узлов.
При разработке кластеров можно выделить два подхода. Первый подход состоит в создании небольших кластерных систем. В кластер объединяются полнофункциональные компьютеры, которые продолжают работать как самостоятельные единицы, например, компьютеры учебного класса или рабочие станции лаборатории. Второй подход заключается в целенаправленном создании мощных вычислительных ресурсов. Системные блоки компьютеров компактно размещают-
ся в специальных стойках, а для управления системой и запуска задач выделяется один или несколько полнофункциональных компьютеров, называемых хост-компьютерами. В этом случае нет необходимости снабжать компьютеры вычислительных узлов графическими картами, мониторами, дисковыми накопителями и другим периферийным оборудованием, что значительно удешевляет стоимость системы.
Разработано множество технологий объединения компьютеров в кластер. Наиболее широко в данное время применяется технология Ethernet, что обусловлено простотой ее использования и низкой стоимостью коммуникационного оборудования. Однако за это приходится расплачиваться заведомо недостаточной скоростью обменов.
Разработчики пакета подпрограмм ScaLAPACK, предназначенного для решения задач линейной алгебры на многопроцессорных системах, в которых велика доля коммуникационных операций, формулируют требование к многопроцессорной системе следующим образом: «Скорость межпроцессорных обменов между двумя узлами, измеренная в МБ/с, должна быть не менее 1/10 пиковой производительности вычислительного узла, измеренной в MFLOPS».
Топологии кластеров
Рассмотрим топологии, характерные для так называемых «малых» кластеров, состоящих из двух - четырех узлов.
Топология кластерных пар используется при организации двухили четырехузловых кластеров (рис.5.5.3 ). Узлы группируются попарно, дисковые массивы присоединяются к обоим узлам, входящим в состав пары, причем каждый узел пары имеет доступ ко всем дисковым массивам данной пары. Один из узлов пары используется как резервный для другого.
Четырехузловая кластерная пара представляет собой простое расширение двухузловой топологии. Обе кластерные пары с точки зрения администрирования и настройки рассматриваются как единое целое.
Данная топология может быть применена для организации кластеров с высокой готовностью данных, но отказоустойчивость реализуется только в пределах пары, так как принадлежащие паре устройства хранения информации не имеют физического соединения с другой парой.

Коммутатор | ||||||||||
кластера | кластера | кластера | кластера |
|||||||
Дисковый | Дисковый | Дисковый | Дисковый |
|||||||
Рис. 5.5.3. Топология кластерных пар
Топология + 1 позволяет создавать кластеры из двух, трех и четырех узлов (рис.5.5.4 ). Каждый дисковый массив подключается только к двум узлам кластера. Дисковые массивы организованы по схеме RAID1 (mirroring). Один сервер имеет соединение со всеми дисковыми массивами и служит в качестве резервного для всех остальных (основных или активных) узлов. Резервный сервер может использоваться для обеспечения высокой степени готовности в паре с любым из активных узлов.
Коммутатор | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
кластера | кластера | кластера | кластера |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Коммутатор | ||||||||
кластера | кластера | кластера | кластера |
|||||
Коммутатор
Дисковый | Дисковый | Дисковый |
|||||
Рис. 5.5.5. Топология ×
Только в этой топологии все узлы кластера имеют доступ ко всем дисковым массивам, которые, в свою очередь, строятся по схеме RAID1 (mirroring). Масштабируемость топологии проявляется в простоте добавления к кластеру дополнительных узлов и дисковых массивов без изменения соединений в системе.
кластера
кластера
кластера
кластера
Дисковый
Дисковый
Дисковый
Дисковый
Рис. 5.5.6. Топология с полностью раздельным доступом
Топология с полностью раздельным доступом допускает соединение каждого дискового массива только с одним узлом кластера (рис. 5.5.6 ). Рекомендуется лишь для тех приложений, для которых характерна архитектура полностью раздельного доступа.
Контрольные вопросы
1. Дайте определение кластерной вычислительной системы.
2. Назовите основные достоинства и недостатки кластерных вычислительных систем.
3. Какие классификации кластерных вычислительных систем вы
4. Какие топологии кластерных систем вам известны? Назовите их достоинства и недостатки.
Литература
1. Архитектуры и топологии многопроцессорных вычислительных систем / А.В. Богданов, В.В. Корхов, В.В. Мареев, Е.Н. Станкова . - М.: ИНТУИТ.РУ, 2004. - 176 с.
2. Микропроцессорные системы: учеб. пособие для вузов /
Е.К. Александров, Р.И. Грушвицкий, М.С. Куприянов и др.; под ред. Д.В. Пузанкова. - СПб.: Политехника, 2002. - 935 с.
Бурное развитие информационных технологий, рост обрабатываемых и передаваемых данных и в то же время повышение требований к надежности, степени готовности, отказоустойчивости и масштабируемости заставляют по-новому взглянуть на уже далеко не молодую технологию кластеризации. Эта технология позволяет создавать довольно гибкие системы, которые будут отвечать всем вышеперечисленным требованиям. Было бы не верно думать, что установка кластера решит абсолютно все проблемы. Но добиться впечатляющих результатов от кластеризации вполне реально. Нужно только четко представлять себе, что это такое, в чем наиболее существенные различия их отдельных разновидностей, а также знать преимущества тех или иных систем - с точки зрения эффективности применения их в вашем деле.
Аналитики из IDC подсчитали, что объем рынка кластеров в 1997 году составлял всего 85 млн. долл., тогда как в прошлом году этот рынок «стоил» уже 367,7 млн. долл. Тенденция роста налицо.
Итак, попробуем расставить все точки над «i». На сегодняшний день не существует какого-либо четкого определения кластера. Более того, нет ни одного стандарта, четко регламентирующего кластер. Однако не стоит отчаиваться, ведь сама суть кластеризации не подразумевает соответствие какому-либо стандарту. Единственное, что определяет, что кластер - это кластер, так это набор требований, предъявляемых к таким системам. Перечислим эти требования (четыре правила):l надежность;l доступность функции (готовность);l масштабируемость;l вычислительная мощность. Исходя из этого сформулируем определение кластера. Кластер - это система произвольных устройств (серверы, дисковые накопители, системы хранения и пр.), обеспечивающих отказоустойчивость на уровне 99,999%, а также удовлетворяющая «четырем правилам». Для примера: серверный кластер - это группа серверов (обычно называемых узлами кластера), соединенных и сконфигурированных таким образом, чтобы предоставлять пользователю доступ к кластеру как к единому целостному ресурсу.
Отказоустойчивость
Несомненно, основной характеристикой в кластере является отказоустойчивость. Это подтверждает и опрос пользователей: 95% опрошенных ответили, что в кластерах им необходимы надежность и отказоустойчивость. Однако не следует смешивать эти два понятия. Под отказоустойчивостью понимается доступность тех или иных функций в случае сбоя, другими словами, это резервирование функций и распределение нагрузки. А под надежностью понимается набор средств обеспечения защиты от сбоев. Такие требования к надежности и отказоустойчивости кластерных систем обусловлены спецификой их использования. Приведем небольшой пример. Кластер обслуживает систему электронных платежей, поэтому если клиент в какой-то момент останется без обслуживания для компании-оператора, это ему будет дорого стоить. Другими словами, система должна работать в непрерывном режиме 24 часа в сутки и семь дней в неделю (7Ѕ24). При этом отказоустойчивости в 99% явно не достаточно, так как это означает, что почти четыре дня в году информационная система предприятия или оператора будет неработоспособной. Это может показаться не таким уж и большим сроком, учитывая профилактические работы и техническое обслуживание системы. Но сегодняшнему клиенту абсолютно безразличны причины, по которым система не работает. Ему нужны услуги. Итак, приемлемой цифрой для отказоустойчивости становится 99,999%, что эквивалентно 5 минутам в год. Таких показателей позволяет достичь сама архитектура кластера. Приведем пример серверного кластера: каждый сервер в кластере остается относительно независимым, то есть его можно остановить и выключить (например, для проведения профилактических работ или установки дополнительного оборудования), не нарушая работоспособность кластера в целом. Тесное взаимодействие серверов, образующих кластер (узлов кластера), гарантирует максимальную производительность и минимальное время простоя приложений за счет того, что:l в случае сбоя программного обеспечения на одном узле приложение продолжает функционировать (либо автоматически перезапускается) на других узлах кластера;l сбой или отказ узла (или узлов) кластера по любой причине (включая ошибки персонала) не означает выхода из строя кластера в целом;l профилактические и ремонтные работы, реконфигурацию и смену версий программного обеспечения в большинстве случаев можно осуществлять на узлах кластера поочередно, не прерывая работу приложений на других узлах кластера.Возможные простои, которые не в состоянии предотвратить обычные системы, в кластере оборачиваются либо некоторым снижением производительности (если узлы выключаются из работы), либо существенным сокращением (приложения недоступны только на короткий промежуток времени, необходимый для переключения на другой узел), что позволяет обеспечить уровень готовности в 99,99%.Масштабируемость
Высокая стоимость кластерных систем обусловлена их сложностью. Поэтому масштабируемость кластера довольно актуальна. Ведь компьютеры, производительность которых удовлетворяет сегодняшние требования, не обязательно будет удовлетворять их и в будущем. Практически при любом ресурсе в системе рано или поздно приходится сталкиваться с проблемой производительности. В этом случае возможно два варианта масштабирования: горизонтальное и вертикальное. Большинство компьютерных систем допускают несколько способов повышения их производительности: добавление памяти, увеличение числа процессоров в многопроцессорных системах или добавление новых адаптеров или дисков. Такое масштабирование называется вертикальным и позволяет временно улучшить производительность системы. Однако в системе будет установлено максимальное поддерживаемое количество памяти, процессоров или дисков, системные ресурсы будут исчерпаны. И пользователь столкнется с той же проблемой улучшения характеристик компьютерной системы, что и ранее.Горизонтальное масштабирование предоставляет возможность добавлять в систему дополнительные компьютеры и распределять работу между ними. Таким образом, производительность новой системы в целом выходит за пределы предыдущей. Естественным ограничением такой системы будет программное обеспечение, которые вы решите на ней запускать. Самым простым примером использования такой системы является распределение различных приложений между разными компонентами системы. Например, вы можете переместить ваши офисные приложения на один кластерный узел приложения для Web на другой, корпоративные базы данных - на третий. Однако здесь возникает вопрос взаимодействия этих приложений между собой. И в этом случае масштабируемость обычно ограничивается данными, используемыми в приложениях. Различным приложениям, требующим доступ к одним и тем же данным, необходим способ, обеспечивающий доступ к данным с различных узлов такой системы. Решением в этом случае становятся технологии, которые, собственно, и делают кластер кластером, а не системой соединенных вместе машин. При этом, естественно, остается возможность вертикального масштабирования кластерной системы. Таким образом, за счет вертикального и горизонтального масштабирования кластерная модель обеспечивает серьезную защиту инвестиций потребителей.В качестве варианта горизонтального масштабирования стоит также отметить использование группы компьютеров, соединенных через коммутатор, распределяющий нагрузку (технология Load Balancing). Об этом довольно популярном варианте мы подробно расскажем в следующей статье. Здесь мы лишь отметим невысокую стоимость такого решения, в основном слагаемую из цены коммутатора (6 тыс. долл. и выше - в зависимости от функционального оснащения) и хост-адаптер (порядка нескольких сот долларов за каждый; хотя, конечно, можно использовать и обыкновенные сетевые карты). Такие решения находят основное применение на Web-узлах с высоким трафиком, где один сервер не справляется с обработкой всех поступающих запросов. Возможность распределения нагрузки между серверными узлами такой системы позволяет создавать на многих серверах единый Web-узел.Beowulf, или Вычислительная мощность
Часто решения, похожие на вышеописанные, носят названия Beowulf-кластера. Такие системы прежде всего рассчитаны на максимальную вычислительную мощность. Поэтому дополнительные системы повышения надежности и отказоустойчивости просто не предусматриваются. Такое решение отличается чрезвычайно привлекательной ценой, и, наверное, поэтому наибольшую популярность приобрело во многих образовательных и научно-исследовательских организациях. Проект Beowulf появился в 1994 году - возникла идея создавать параллельные вычислительные системы (кластеры) из общедоступных компьютеров на базе Intel и недорогих Ethernet-сетей, устанавливая на эти компьютеры Linux и одну из бесплатно распространяемых коммуникационных библиотек (PVM, а затем MPI). Оказалось, что на многих классах задач и при достаточном числе узлов такие системы дают производительность, сравнимую с суперкомпьютерной. Как показывает практика, построить такую систему довольно просто. Все, что для этого нужно, это высокопроизводительный коммутатор и несколько подсоединенных к нему рабочих станций (серверов) с установленной операционной системой Linux. Однако этого недостаточно. Для того чтобы эта груда железа ожила, необходимо специальное программное обеспечение для параллельных вычислений.Наиболее распространенным интерфейсом параллельного программирования в модели передачи сообщений является MPI (Message Passing Interface). Название «Интерфейс передачи сообщений» говорит само за себя. Это хорошо стандартизованный механизм для построения параллельных программ в модели обмена сообщениями. Существуют бесплатные (!) и коммерческие реализации почти для всех суперкомпьютерных платформ, а также для сетей рабочих станций UNIX и Windows NT. В настоящее время MPI - наиболее широко используемый и динамично развивающийся интерфейс своего класса. Рекомендуемая бесплатная реализация MPI - пакет MPICH, разработанный в Аргоннской Национальной Лаборатории. Стандартизацией MPI занимается MPI Forum. Последняя версия стандарта - 2.0. В этой версии к MPI добавлены такие важные функции, как динамическое управление процессами, односторонние коммуникации (Put/Get), параллельный ввод-вывод.Постоянный спрос на высокие вычислительные мощности обусловил появление привлекательного для многих производителей рынка. Некоторые из них разработали собственные технологии соединения компьютеров в кластер. Наиболее известные из них - Myrinet производства MyriCom и cLAN фирмы Giganet. Myrinet является открытым стандартом. Для его реализации MyriCom предлагает широкий выбор сетевого оборудования по сравнительно невысоким ценам. На физическом уровне поддерживаются сетевые среды SAN (System Area Network), LAN (CL-2) и оптоволокно. Технология Myrinet дает высокие возможности масштабирования сети и в настоящее время очень широко используется при построении высокопроизводительных кластеров. Giganet занимается разработкой программных и аппаратных средств для непосредственного взаимодействия центральных процессорных устройств серверов кластера на гигабитных скоростях, минуя функции ОС. Стоимость решения составляет: около 2500 долл. - за 8-портовый коммутатор, 150 долл. - за адаптер для Myrinet, около 6250 долл. - за 8-портовый коммутатор и 800 долл. - за адаптер для Giganet. Последняя, кстати, получила на выставке Microsoft Tech Ed 2000 премию «Best of Show». В качестве примера приведем реализацию Beowulf-кластера в Институте высокопроизводительных вычислений и баз данных Министерства науки и технической политики РФ. Кластер, получивший название «ПАРИТЕТ», создан на базе общедоступных комплектующих для персональных компьютеров и рабочих станций и обеспечивает суммарную пиковую производительность 3,2 GFLOP/sec. Кластер состоит из четырех двухпроцессорных вычислительных узлов, на базе процессоров Intel Pentium II/450MHz. На каждом узле установлена оперативная память объемом 512 Мбайт и 10-гигабайтный жесткий диск на интерфейсе Ultra Wide SCSI. Вычислительные узлы кластера объединены высокопроизводительным коммутатором Myrinet (каналы с пропускной способностью 1,28 Гбайт/с, полный дуплекс). Имеется также резервная сеть, используемая для управления и конфигурирования (100 Mbit Fast Ethernet). На узлах вычислительного кластера установлена операционная система Linux (дистрибутив Red Hat 5,2). Для программирования параллельных приложений используются интерфейсы передачи сообщений MPI/PVM.Мини-кластер от Dell и Compaq
Помимо коммутаторного решения для построения кластера существует еще целый ряд решений - как аппаратных, так и программных. Некоторые решения являются комплексными и поставляются «As is» - «все в одной коробке». Последний вариант - назовем его «кластер в коробке» - также является довольно популярным решением, поскольку рассчитан на массовый рынок и является кластером начального уровня (по производительности и параметрам масштабирования). Однако построение таких систем, взаимосвязь внутренних компонентов, надежность и отказоустойчивость полностью соответствуют «большим» системам. Для того чтобы разобраться, как устроен кластер, рассмотрим две похожие системы производства - Compaq и Dell. Кластеры от этих известных игроков компьютерного рынка построены из двух серверов DELL - PowerEdge 6100 либо PowerEdge 4200 и, в свою очередь, Compaq - Proliant 1850R. В качестве программного обеспечения используется Microsoft Cluster Server (Compaq, Dell) или Novell High-Availability Services for NetWare 4.0 / Clustering Services for NetWare 5.0 (Compaq). Программное обеспечение позволяет сконфигурировать два сервера таким образом, что, если в одном из серверов кластера происходит сбой, выполняемая им работа и приложения будут сразу же автоматически перенесены на другой сервер, что позволяет устранить простои. Оба сервера кластера предоставляют свои ресурсы для выполнения производственной работы, поэтому ни один из них не простаивает зря в ожидании, пока другой не выйдет из строя.Представленная на рисунке конфигурация является типичным кластером с реализацией принципа безотказности, обеспечивающим высокую степень работоспособности и дублирования компонентов на системном уровне. Связь между двумя серверами осуществляется по так называемому пульсирующему соединению (Heartbeat) выделенного участка локальной сети. При возникновении сбоя на основном сервере второй сервер, следящий за поступающими по пульсирующему соединению сообщениями, узнает об отключении основного сервера и перекладывает на себя рабочую нагрузку, выполнявшуюся вышедшей из строя машиной. В число выполняемых функций входит запуск прикладных программ, процессов и обслуживания, требуемых для ответа на запросы клиентов на предоставление доступа к вышедшему из строя серверу. Хотя каждый из серверов кластера должен иметь все ресурсы, требуемые для возложения на себя функций другого сервера, основные выполняемые обязанности могут быть абсолютно разными. Вторичный сервер, входящий в кластер с реализацией принципа безотказности, отвечает требованию предоставления возможности «горячего» резервирования, но помимо этого он может выполнять и свои собственные приложения. Однако, несмотря на массовое дублирование ресурсов, у такого кластера есть «узкое» место (bottle neck) - интерфейс шины SCSI и разделяемой системы внешней памяти, выход которых из строя влечет за собой сбой кластера. Хотя, по утверждениям производителей, вероятность этого ничтожно мала.Такие мини-кластеры прежде всего рассчитаны на автономную работу без постоянного контроля и администрирования. В качестве примера использования можно привести решение для удаленных офисов больших компаний для обеспечения высокой готовности (7Ѕ24) наиболее ответственных приложений (баз данных, почтовых систем и т.д.). С учетом повышения спроса на мощные и в то же время отказоустойчивые системы начального уровня рынок для этих кластеров выглядит довольно благоприятным. Единственное «но» в том, что не каждый потенциальный потребитель кластерных систем готов выложить за двухсерверную систему около 20 тыс. долл.Сухой остаток
В качестве резюме следует отметить, что у кластеров наконец-то появился массовый рынок. Такой вывод легко можно сделать исходя из прогнозов аналитиков Standish Group International, которые утверждают, что в следующие два года общемировой рост количества установленных кластерных систем составит 160%. Кроме того, аналитики из IDC подсчитали, что объем рынка кластеров в 1997 году составлял всего 85 млн. долл., а в прошлом году этот рынок «стоил» уже 367,7 млн. долл. Тенденция роста налицо. И действительно, потребность в кластерных решениях сегодня возникает не только в крупных центрах обработки данных, но и в небольших компаниях, которые не хотят жить по принципу «скупой платит дважды» и вкладывают свои деньги в высоконадежные и легкомасштабируемые кластерные системы. Благо, что вариантов реализации кластера более чем достаточно. Однако при выборе какого-либо решения не следует забывать, что все параметры кластера взаимозависимы. Другими словами, нужно четко определить приоритеты на необходимые функциональные возможности кластера, поскольку при увеличении производительности уменьшается степень готовности (доступность). Увеличение производительности и обеспечение требуемого уровня готовности неизбежно ведет к росту стоимости решения. Таким образом, пользователю необходимо сделать самое важное - найти золотую середину возможностей кластера на текущий момент. Это сделать тем труднее, чем больше разнообразных решений предлагается сегодня на рынке кластеров.При подготовке статьи использованы материалы WWW-серверов: http://www.dell.ru/ , http://www.compaq.ru/ , http://www.ibm.ru/ , http://www.parallel.ru/ , http://www.giganet.com/ , http://www.myri.com/КомпьютерПресс 10"2000
Вершина современной инженерной мысли - сервер Hewlett-Packard Integrity Model SD64A. Огромная SMP-система, объединяющая в себе 64 процессора Intel Itanium 2 с частотой 1,6 ГГц и 256 Гбайт оперативной памяти, колоссальная производительность, внушительная цена - 6,5 млн. долларов…
Вершина современной инженерной мысли - сервер Hewlett-Packard Integrity Model SD64A. Огромная SMP-система, объединяющая в себе 64 процессора Intel Itanium 2 с частотой 1,6 ГГц и 256 Гбайт оперативной памяти, колоссальная производительность, внушительная цена - 6,5 млн. долларов…
Нижняя строчка свежего рейтинга пятисот самых быстрых компьютеров мира: принадлежащий группе компаний SunTrust Banks Florida кластер на основе блейд-серверов HP ProLiant BL-25p. 480 процессоров Intel Xeon 3,2 ГГц; 240 Гбайт оперативной памяти. Цена - меньше миллиона долларов.
Как-то странно получается, согласитесь: шесть с половиной миллионов долларов за 64-процессорный сервер и вдесятеро меньше - за примерно аналогичный по объему памяти и дисковой подсистеме, но уже 480-процессорный суперкомпьютер, причем от того же самого производителя. Впрочем, странно это только на первый взгляд: общего у двух компьютеров совсем немного. SD64A - представитель "классического" направления симметричной многопроцессорности (SMP), хорошо знакомого нам по обычным серверам и многоядерным системам, позволяющий использовать "традиционное" параллельное ПО. Это кучка процессоров, много оперативной памяти и очень сложная система, сводящая их (и периферию сервера) в единое целое; причем даже весьма недешевые процессоры (по четыре тысячи долларов за каждый) и огромный объем оперативной памяти (по двести долларов за каждый гигабайт) - лишь малая часть стоимости этой "объединяющей" части сервера. Машина же SunTrust Bank Florida - представитель современного "кластерного" направления и по сути - просто набор соединенных в Ethernet-сеть обычных "недорогих" (по паре тысяч долларов за штуку) компьютеров. Серверная стойка, набор кабелей, система питания и охлаждения - вот и все, что эти компьютеры объединяет.
Что такое кластер?
Стандартное определение таково: кластер - это набор вычислительных узлов (вполне самостоятельных компьютеров), связанных высокоскоростной сетью (интерконнектом) и объединенных в логическое целое специальным программным обеспечением. Фактически простейший кластер можно собрать из нескольких персоналок, находящихся в одной локальной сети, просто установив на них соответствующее ПО[Всех желающих сделать это самостоятельно отсылаем к статье Михаила Попова "Еда и кластеры на скорую руку" (offline.computerra.ru/2002/430/15844), которая до сих пор актуальна]. Однако подобные схемы - скорее редкость, нежели правило: обычно кластеры (даже недорогие) собираются из специально выделенных для этой цели компьютеров и связываются друг с другом отдельной локальной сетью.
В чем идея подобного объединения? Кластеры ассоциируются у нас с суперкомпьютерами, круглые сутки решающими на десятках, сотнях и тысячах вычислительных узлов какую-нибудь сверхбольшую задачу, но на практике существует и множество куда более "приземленных" кластерных применений. Часто встречаются кластеры, в которых одни узлы, дублируя другие, готовы в любой момент перехватить управление, или, например, одни узлы, проверяя получаемые с другого узла результаты, радикально повышают надежность системы. Еще одно популярное применение кластеров - решение задачи массового обслуживания, когда серверу приходится отвечать на большое количество независимых запросов, которые можно легко раскидать по разным вычислительным узлам[Обычно эту штуку называют серверной фермой, именно по такому принципу работает Google]. Однако рассказывать об этих двух, если угодно, "вырожденных" случаях кластерных систем практически нечего - из их краткого описания и так ясно, как они работают; поэтому разговор наш пойдет именно о суперкомпьютерах.
Итак, суперкомпьютер-кластер. Он состоит из трех основных компонентов: собственно "вычислялок" - компьютеров, образующих узлы кластера; интерконнекта, соединяющего эти узлы в сеть, и программного обеспечения, заставляющего всю конструкцию "почувствовать" себя единым компьютером. В роли вычислительных узлов может выступать что угодно - от старой никому не нужной персоналки до современного четырехпроцессорного сервера, причем их количество ничем не ограниченно (ну разве что площадью помещения да здравым смыслом). Чем быстрее и чем больше - тем лучше; и как эти узлы устроены, тоже неважно[Обычно для упрощения решения и непростой задачи балансировки нагрузки на разные узлы кластера все узлы в кластере делают одинаковыми, но даже это требование не абсолютно]. Гораздо интереснее обстоят дела с интерконнектом и программным обеспечением.
Как устроен кластер?
История развития кластерных систем неразрывно связана с развитием сетевых технологий. Дело в том, что, чем больше элементов в кластере и чем они быстрее, (и, соответственно, чем выше быстродействие всего кластера), тем более жесткие требования предъявляются к скорости интерконнекта. Можно собрать кластерную систему хоть из 10 тысяч узлов, но если вы не обеспечите достаточной скорости обмена данными, то производительность компьютера по-прежнему оставит желать лучшего. А поскольку кластеры в высокопроизводительных вычислениях - это практически всегда суперкомпьютеры[Программирование для кластеров - весьма трудоемкая задача, и если есть возможность обойтись обычным сервером SMP-архитектуры с эквивалентной производительностью, то так и предпочитают делать. Поэтому кластеры используются только там, где SMP обходится слишком дорого, а со всех практических точек зрения требующие такого количества ресурсов машины - это уже суперкомпьютеры], то и интерконнект для них просто обязан быть очень быстрым, иначе полностью раскрыть свои возможности кластер не сможет. В результате практически все известные сетевые технологии хотя бы раз использовались для создания кластеров[Я даже слышал о попытках использования в качестве интерконнекта стандартных портов USB], причем разработчики зачастую не ограничивались стандартом и изобретали "фирменные" кластерные решения, как, например, интерконнект, основанный на нескольких линиях Ethernet, включаемых между парой компьютеров в параллель. К счастью, с повсеместным распространением гигабитных сетевых карт, ситуация в этой области становится проще[Почти половину списка суперкомпьютеров Top 500 составляют кластеры, построенные на основе Gigabit Ethernet], - они довольно дешевы, и в большинстве случаев предоставляемых ими скоростей вполне достаточно.
Вообще, по пропускной способности интерконнект почти дошел до разумного предела: так, постепенно появляющиеся на рынке 10-гигабитные адаптеры Ethernet вплотную подобрались к скоростям внутренних шин компьютера, и если создать некий гипотетический 100-гигабитный Ethernet, то не найдется ни одного компьютера, способного пропустить через себя такой огромный поток данных. Но на практике десятигигабитная локальная сеть, несмотря на всю свою перспективность, встречается редко - технология Ethernet допускает использование только топологии "звезда", а в подобной системе центральный коммутатор, к которому подключаются все остальные элементы, обязательно будет узким местом. Кроме того, у Ethernet-сетей довольно большая латентность[Время между отправкой запроса одним узлом и получением этого запроса другим узлом], что тоже затрудняет их использование в "тесно связанных" задачах, где отдельные вычислительные узлы должны активно обмениваться информацией. Поэтому несмотря на почти предельную пропускную способность Ethernet-решений в кластерах широко используются сети со специфической топологией - старая добрая Myrinet, дорогая элитная Quadrics, новенькая InfiniBand и др. Все эти технологии "заточены" под распределенные приложения и обеспечивают минимальную латентность исполнения команд и максимальную производительность. Вместо традиционной "звезды" здесь из вычислительных элементов строятся плоские и пространственные решетки, многомерные гиперкубы, поверхности трехмерного тора и другие "топологически хитрые" объекты. Такой подход позволяет одновременно передавать множество данных по сети, гарантируя отсутствие узких мест и увеличивая суммарную пропускную способность.
Как развитие идей быстрого интерконнекта отметим, например, адаптеры сети InfiniBand, подключающиеся через специальный слот HTX к процессорной шине HyperTransport. Фактически адаптер напрямую подключается к процессору[Напомним, что в многопроцессорных системах на базе AMD Opteron межпроцессорное взаимодействие происходит именно по этой шине]! Лучшие образцы подобных решений обеспечивают столь высокую производительность, что построенные на их основе кластеры вплотную приближаются по характеристикам к классическим SMP-системам, а то и превосходят их. Так, в ближайшие несколько месяцев на рынке должен появиться интереснейший чип под названием Chorus, который по четырем шинам HyperTransport подключается к четырем или двум процессорам AMD Opteron, расположенным на одной с ним материнской плате, и с помощью трех линков InfiniBand может подключаться еще к трем другим "Хорусам", контролирующим другие четверки (или пары) процессоров. Один Chorus - это одна материнская плата и один сравнительно независимый узел с несколькими процессорами, подключаемый стандартными кабелями InfiniBand к остальным узлам. Внешне вроде бы получается кластер, но - только внешне: оперативная память у всех материнских плат общая. Всего в текущем варианте может объединяться до восьми "Хорусов" (и соответственно до 32 процессоров), причем все процессоры будут работать уже не как кластер, а как единая SUMA-система, сохраняя, однако, главное достоинство кластеров - невысокую стоимость и возможность наращивания мощности. Такой вот получается "суперкластеринг", стирающий границы между кластерами и SMP.
Впрочем, все эти новомодные решения совсем не дешевы, - а ведь начинали мы с невысокой себестоимости кластера. Поэтому "Хорусы" да "Инфинибенды", стоящие солидных денег (несколько тысяч долларов на каждый узел кластера, что хоть и гораздо меньше, чем у аналогичных SMP-систем, но все равно дорого), встречаются нечасто. В секторе "академических" суперкомпьютеров, принадлежащих университетам, обычно используются самые дешевые решения, так называемые Beowulf–кластеры, состоящие из набора персоналок, соединенных гигабитной или даже стомегабитной Ethеrnet-сетью и работающих под управлением бесплатных операционных систем типа Linux. Несмотря на то что собираются такие системы буквально "на коленке", иногда из них все равно вырастают сенсации: к примеру, "биг-мак" - собранный из 1100 обычных "макинтошей" самодельный кластер, обошедшийся организаторам всего в 5,2 млн. долларов и умудрившийся занять в 2003 году третье место в рейтинге Top 500.
GRID-сети
Можно ли "продолжить" кластеры в сторону меньшей связанности точно так же, как, "продолжив" их в другом направлении, мы пришли к чипу Chorus и "почти SMP"? Можно! При этом мы отказываемся от построения специальной кластерной сети, а пытаемся использовать уже имеющиеся ресурсы - локальные сети и образующие их компьютеры. Общее название подобного рода решений - GRID-технологии, или технологии распределенных вычислений (вы наверняка с ними хорошо знакомы по таким проектам, как Distributed.Net или SETI@Home; машины добровольцев, участвующих в этих проектах, загружены разнообразными расчетами, ведущимися в то время, когда ПК хозяину не нужен). Ограничиваться достигнутым создатели GRID-систем не собираются и ставят перед собой амбициозную цель - сделать вычислительные мощности таким же доступным ресурсом, как электричество или газ в квартире. В идеале все компьютеры, подключенные к Интернету в рамках GRID, должны быть объединены в некое подобие кластера, и в то время, когда ваша машина простаивает, ее ресурсы будут доступны другим пользователям, а когда у вас возникает необходимость в больших мощностях, вам помогают "чужие" свободные компьютеры, которых в Сети предостаточно (кто-то отошел попить кофе, кто-то занимается серфингом или другими не загружающими процессор делами). Приоритетный доступ к ресурсам GRID будут иметь ученые, которые получат в распоряжение в буквальном смысле всемирный суперкомпьютер; но и обычные пользователи тоже внакладе не останутся.
Впрочем, если на словах все выглядит так замечательно, то почему это светлое будущее до сих пор не настало? Все дело в том, что при создании GRID возникают нетривиальные проблемы, решать которые пока никто толком не научился. В отличие от простого кластера при создании подобной системы приходится учитывать такие факторы, как неоднородность вычислительных узлов, низкая пропускная способность и нестабильность каналов, куда большее количество одновременно выполняемых задач, непредсказуемое поведение элементов системы, ну и, конечно, недоброжелательность некоторых пользователей. Судите сами: неоднородность нашей сети (причем очень сильная) возникает оттого, что к Интернету подключены самые разные компьютеры; у них разные возможности, разные линии связи и разные хозяева (режим работы у каждого свой). К примеру, где-то в школе есть гигабитная сеть из трех десятков почти всегда доступных, но не очень быстрых компьютеров, выключающихся на ночь в строго определенное время; а где-то стоит одинокий компьютер с завидной производительностью, непредсказуемо подключаемый к Сети по слабенькому дайлапу: так вот, в первом случае будут очень хорошо выполняться одни задачи, а во втором - совершенно другие. И для обеспечения высокой производительности системы в целом все это надо как-то анализировать и прогнозировать, чтобы оптимальным образом спланировать выполнение различных операций.
Далее. С плохими каналами связи трудно что-то сделать, но ведь можно не ждать светлого будущего, когда Интернет станет быстрым и надежным, а уже сейчас применять действенные методы сжатия и контроля целостности передаваемой информации. Вполне возможно, что резко повысившаяся за счет этого пропускная способность каналов скомпенсирует выросшую из-за необходимости сжатия и контроля вычислительную нагрузку на компьютеры сети.
К сожалению, большое количество одновременно выполняемых задач существенно увеличивает нагрузку на управляющие элементы GRID-сети и осложняет задачу эффективного планирования, поскольку уже сами "управленцы", контролирующие эту сеть, зачастую начинают требовать для себя отдельный суперкомпьютер, ссылаясь на необходимость сложного контроля и планирования. А планировать и осуществлять контроль им действительно нелегко, и не только из-за неоднородности планируемых ресурсов, но и по причине их "ненадежности". Вот, к примеру, непредсказуемое поведение хозяина компьютера - это отдельная песня. В обычном кластере выход элемента из строя - нештатная ситуация, которая влечет за собой остановку вычислений и ремонтные работы, в GRID же отказ одного элемента - нормальная ситуация (почему бы не выключить компьютер, когда вам это надо?), ее нужно корректно обработать и передать невыполненное задание на другой узел или же заранее назначать одно и то же задание нескольким узлам.
И наконец, никуда не деться в GRID-сетях от недоброжелательных пользователей (не зря же сейчас очень много делается для защиты информации). Ведь нам нужно как-то распределять и планировать во всей сети задания от всех ее пользователей, - и мало ли чего какой-нибудь Василий Пупкин мог туда запустить? Сегодня и без того вирусы, заражающие подключенные к Интернету компьютеры специальными троянами ("зомбирование") и создающие целые "зомби-сети" из зараженных машин, готовых делать все, что заблагорассудится автору вируса (проводить ли распределенные DDoS-атаки или рассылать спам - неважно), представляют собой серьезнейшую угрозу, а тут - у любого человека появляется возможность посредством штатной системы рассылки распространить любой код на сотни и тысячи персоналок. И хотя эта проблема в принципе решаема (например, путем создания для выполняемых задач виртуальных машин - благо вскоре технологии аппаратной виртуализации , которые позволят это сделать без особого труда, станут штатной принадлежностью большинства новых компьютеров), то как защититься от банальной "шалости" в виде запуска бессмысленного кода (скажем, бесконечного цикла) и замусоривания им GRID-сети?
На самом деле все не так грустно, и многое в GRID-направлении уже сделано. Запущены и функционируют десятки проектов, использующих распределенные вычисления для научных и околонаучных целей; запущены и GRID-сети для "внутриуниверситетского" научного использования - в частности, CrossGrid, DataGrid и EUROGRID.
Программное обеспечение для кластеров
А вот здесь все очевидно и просто: фактически на протяжении последних пяти лет для кластерных вычислений существует один-единственный стандарт - MPI (Message Passing Interface). Программы, написанные с использованием MPI, абсолютно переносимы - их можно запускать и на SMP-машине, и на NUMA, и на любой разновидности кластера, и на GRID-сети, причем из любой операционной системы. Конкретных реализаций MPI довольно много (к примеру, каждый поставщик "фирменного" быстрого интерконнекта может предлагать свой вариант MPI-библиотеки для его решения), однако благодаря совместимости выбирать из них можно любой, какой вам приглянется (например, быстродействием или удобством настройки). Очень часто используется такой OpenSource-проект, как MPICH, обеспечивающий работу на более чем двух десятках различных платформ, включая самые популярные - SMP (межпроцессное взаимодействие через разделяемую память) и кластеры с интерконнектом Ethernet (межпроцессное взаимодействие поверх протокола TCP/IP), - если доведется когда-нибудь настраивать кластер, то начать советую именно с него.
На "классических" SMP-системах и некоторых NUMA’х реализация параллельных вычислений с использованием MPI заметно уступает по производительности более "аппаратно ориентированным" многопоточным приложениям, поэтому наряду с "чистыми" MPI-решениями встречаются "гибриды", в которых на кластере "в целом" программа работает с использованием MPI, но на каждом конкретном узле сети (а каждый узел кластера - это зачастую SMP-система) работает MPI-процесс, распараллеленный вручную на несколько потоков. Как правило, это гораздо эффективнее, но и гораздо труднее в реализации, а потому на практике встречается нечасто.
Как уже говорилось, можно выбрать практически любую операционную систему. Традиционно для создания кластеров используется Linux (более 70% систем Top 500) или другие разновидности Unix (оставшиеся 30%), однако последнее время к этому престижному рынку HPC (High Perfomance Computing) присматривается и Microsoft, выпустившая бета-версию Windows Compute Claster Server 2003[Бесплатно скачать эту бету можно ], в состав которой включена микрософтовская версия библиотеки MPI - MSMPI. Так что организация "кластера своими руками" вскоре может стать уделом не только юниксоидов, но и их менее знающих собратьев-администраторов, да и вообще - значительно упроститься.
Напоследок скажем, что кластерные вычисления годятся далеко не для всяких задач. Во-первых, программы под кластерные вычисления нужно "затачивать" вручную, самостоятельно планируя и маршрутизируя потоки данных между отдельными узлами. MPI, правда, сильно упрощает разработку параллельных приложений в том плане, что в нем при понимании сути происходящего соответствующий код очень нагляден и очевиден, и традиционные глюки параллельных программ типа дедлоков или параллельного использования ресурсов практически не возникают. Но вот заставить получающийся код быстро работать на MPI бывает довольно трудно - зачастую для этого приходится серьезно модифицировать сам программируемый алгоритм. В целом нераспараллеливающиеся и труднораспараллеливающиеся программы на MPI реализуются плохо; а все остальные - более или менее хорошо (в смысле - масштабируются до десятков, а в "хорошем" случае - и до тысяч процессоров). И чем больше степень связанности кластера, тем проще извлекать из него выгоду от параллельной обработки данных: на кластере, связанном сетью Myrinet, программа может работать быстро, а на аналогичном кластере, где интерконнектом выступает Fast Ethernet, - попросту не масштабироваться (не получать дополнительного прироста производительности) сверх десяти процессоров. Особенно трудно получить какой-либо выигрыш в GRID-сетях: там вообще, по большому счету, подходят только слабо связанные задачи с минимумом начальных данных и сильным параллелизмом - например, те, в которых приходится перебирать значительное количество вариантов.
Вот такие они - доступные всем суперкомпьютеры сегодняшнего дня. И не только доступные, но и более чем востребованные повсюду, где требуются высокопроизводительные вычисления за умеренные деньги. Даже простой пользователь, увлекающийся рендерингом, может собрать дома из своих машин небольшой кластер (рендеринг параллелится практически идеально, так что никаких ухищрений здесь не понадобится) и резко увеличить производительность труда[К примеру, пакет Maya позволяет организовать кластерный рендеринг даже без привлечения каких-либо сторонних пакетов и библиотек. Достаточно установить его на несколько компьютеров локальной сети и настроить сервер и несколько клиентов].
Высокопроизводительный кластер (группа компьютеров)
Компьютерный кластер - это группа компьютеров объединённых между собой высокоскоростными линиями связи, которые совместно обрабатывают одни и те же запросы и представляются со стороны пользователя как единая вычислительная система.
Главные свойства кластеров
Кластеры состоят из нескольких компьютерных систем;
Они работают как одна вычислительная система (не все);
Кластер управляется и представляется пользователю как одна вычислительная система;
Зачем нужны кластеры
Кластеры можно использовать в разных целях. Кластеры могут создавать отказоустойчивые системы, могут служить для повышения производительности компьютерного узла, а могут быть использовании для трудоёмких вычислений.
Какие бывают кластеры
Отказоустойчивые кластеры
Подобные кластера создают для обеспечения высокого уровня доступности сервиса представляемого кластером. Чем больше количество компьютеров входящих в кластер, тем меньше вероятность отказа представляемого сервиса. Компьютеры, которые входят в кластер, разнесённые географически, так же обеспечивают защиту от стихийных бедствий, террористических атак и других угроз.
Данные кластера могут быть построены по трём основным принципам
- кластеры с холодным резервом - это когда активный узел обрабатывает запросы, а пассивный бездействует, и просто ждёт отказа активного. Пассивный узел начинает работать только после отказа активного. Кластер, построенный по данному принципу, может обеспечить высокую отказоустойчивость, но в момент выключения активного узла, запросы обрабатываемые им в этот момент могут быть утеряны.
- кластер с горячим резервом - это когда все узлы системы совместно обрабатывают запросы, а в случае отказа одного или нескольких узлов, нагрузка распределяется между оставшимися. Данный тип кластера можно так же назвать кластер распределения нагрузки о котором мы поговорим далее, но с поддержкой распределения запросов при отказе одного или нескольких узлов. При использовании данного кластера, так же есть вероятность потери данных, обрабатываемых узлом, который дал сбой.
- кластер с модульной избыточностью - это когда все компьютеры кластера обрабатывают одни и те же запросы параллельно друг другу, а после обработки берётся любое значение. Подобная схема гарантирует выполнение запроса, так как можно взят любой результат обработки запроса.
Кластер распределения нагрузки
Эти кластера создают в основном для повышения производительности, но их можно использовать и для повышения отказоустойчивости, как в случае с отказоустойчивым кластером горячего резерва. В данных кластера запросы распределяются через входные узлы на все остальные узлы кластера.
Вычислительные кластеры
Данный тип кластеров, используется как правило в научных целях. В данных системах, задача разбивается на части, параллельно-выполняемые на всех узлах кластера. Это позволяет существенно сократить время обработки данных по сравнению с одиночными компьютерами.

|
Не забываем оставлять |